
Para configurar IA local en 2026 necesitas tres componentes: LM Studio como motor de inferencia, Open WebUI como interfaz de chat, y una GPU con mínimo 8 GB de VRAM. El setup completo toma entre 20 y 30 minutos. Una vez funcionando, tendrás un chat privado con modelos open source como Qwen 3.6 o Gemma 4, sin enviar datos a servidores externos y sin suscripción mensual.
En esta guía cubrimos todo desde la instalación hasta la búsqueda web integrada, dejando la puerta abierta a setups mas avanzados: agentes autónomos, multi-GPU y fine-tuning.
Que es la IA Local y por que importa en 2026
IA local significa ejecutar modelos de lenguaje (LLMs) en tu propio hardware, en lugar de depender de APIs en la nube como ChatGPT, Claude o Gemini. En 2026, los modelos open source han alcanzado un nivel donde un setup domestico con GPU dedicada puede manejar tareas de redacción, análisis de código y asistencia general con calidad comparable a los servicios comerciales.
Las ventajas practicas son:
- Privacidad total: Ningún dato sale de tu código. Ideal para documentos sensibles, código propietario o conversaciones privadas.
- Sin costo recurrente: Tras la inversión inicial en hardware, no hay suscripción mensual ni límites de tokens.
- Sin censura ni bloqueos: Tu modelo, tus reglas. No hay filtros de seguridad impuestos por terceros.
- Funciona offline: Una vez descargados los modelos, no necesitas conexión a internet.
Requisitos de hardware
El factor más importante es la VRAM (memoria de video). Los modelos se cargan en la GPU y la VRAM determina que tamanos de modelo puedes correr. El ancho de banda de memoria (bandwidth) determina la velocidad de respuesta.
| Nivel | GPU | VRAM | Bandwidth | Modelo recomendado | Velocidad estimada |
|---|---|---|---|---|---|
| Entrada | RTX 4060 | 8 GB GDDR6 | 272 GB/s | Qwen3.6 9B, Gemma 4 9B | 25-40 tok/s |
| Intermedio | RTX 5070 Ti | 16 GB GDDR7 | 800 GB/s | Qwen3.6 27B, Gemma 4 27B | 18-30 tok/s |
| Power user | RTX 5090 | 32 GB GDDR7 | 1792 GB/s | Qwen3.6 35B MoE, Gemma 4 31B | 22-35 tok/s |
Requisitos adicionales:
- RAM del sistema: Minimo 16 GB (32 GB recomendado). El sistema necesita memoria adicional para el SO y las aplicaciones.
- Almacenamiento: Cada modelo ocupa entre 5 y 25 GB en formato GGUF. Con 3-4 modelos necesitas 100 GB libres como minimo.
- CPU: Cualquier CPU moderna con soporte AVX2. No es el cuello de botella pero ayuda en la carga inicial del modelo.
- Fuente de alimentación: Para RTX 5070 Ti, mínimo 750W. Para RTX 5090, mínimo 1000W.
1 Instalar LM Studio
LM Studio es la aplicación que se encarga de ejecutar los modelos de lenguaje en tu GPU. Proporciona una interfaz gráfica para descargar modelos, configurar parámetros de inferencia y exponer una API compatible con OpenAI.
Descarga e instalación
- Visita lmstudio.ai/download
- Descarga la versión para tu sistema operativo (Windows, macOS, Linux)
- Ejecuta el instalador y sigue los pasos por defecto
- Abre LM Studio
Activar el servidor local
LM Studio incluye un servidor API que Open WebUI usara como backend. Para activarlo:
- Haz click en el icono de Server (icono de </> en la barra lateral izquierda)
- En la seccion «Local Server», selecciona el modelo que descargaste
- Verifica que el puerto sea
1234(por defecto) - Haz click en Start Server
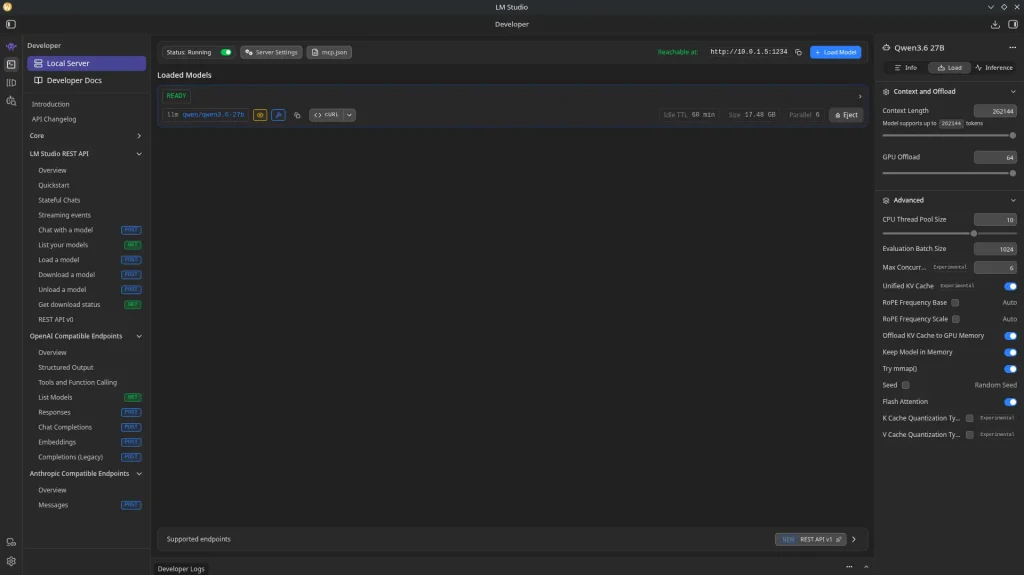
El servidor expone un endpoint compatible con OpenAI en http://localhost:1234/v1. Puedes verificar que funciona ejecutando:
curl http://localhost:1234/v1/modelsDeberias ver una lista con el modelo cargado.
Descargar tu primer modelo
En la barra lateral, ve a la sección de búsqueda (icono de lupa) y busca el modelo según tu GPU:
| Tu GPU | Modelo recomendado | Buscar en LM Studio |
|---|---|---|
| RTX 4060 (8 GB) | Qwen3.6 9B | qwen3.6 9b gguf |
| RTX 5070 Ti (16 GB) | Qwen3.6 27B | qwen3.6 27b gguf |
| RTX 5090 (32 GB) | Qwen3.6 27B | |
Selecciona la version Q4_K_M (cuantificacion 4-bit) — ofrece el mejor equilibrio entre calidad y rendimiento. Haz click en el icono de descarga y espera.
2 Instalar Open WebUI
Open WebUI es una interfaz de chat moderna que se conecta a LM Studio como backend. Proporciona una experiencia similar a ChatGPT pero completamente local, con soporte para multiples modelos, historial de conversaciones, plugins y búsqueda web.
Instalacion via Docker
La forma mas limpia de instalar Open WebUI es con Docker. Si no tienes Docker instalado, descarga Docker Desktop para tu sistema.
# Descargar la imagen de Open WebUI
docker pull ghcr.io/open-webui/open-webui:main
# Ejecutar el contenedor
docker run -d -p 3000:8080 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainSi usas Windows con Docker Desktop, el comando es el mismo. Open WebUI se accedera desde http://localhost:3000.
La primera vez que entres, Open WebUI te pedira crear una cuenta. Crea tu admin y prosigue.
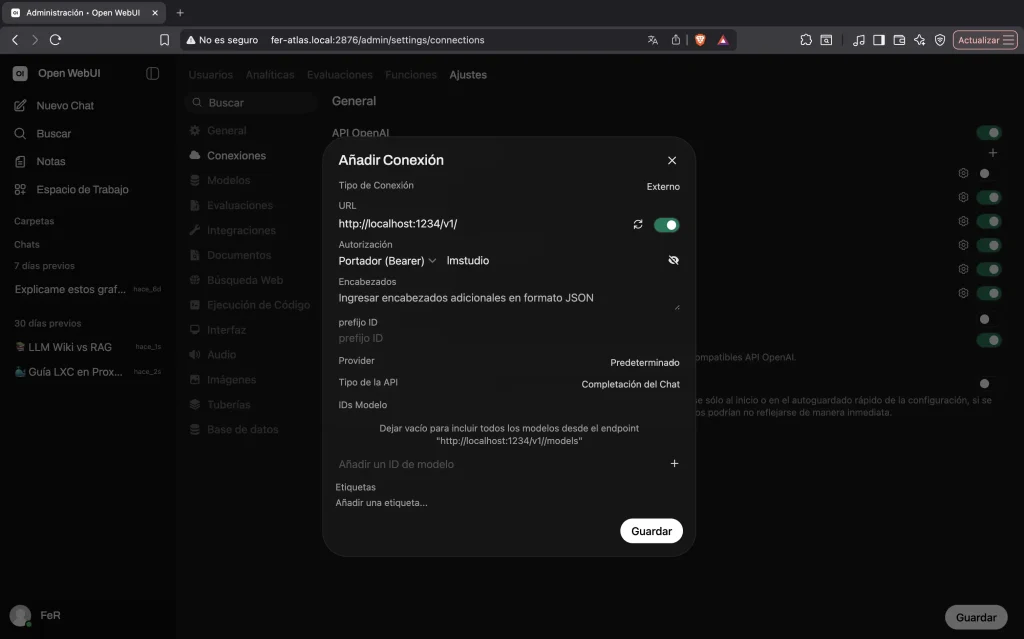
Conectar Open WebUI a LM Studio
Ahora conectamos Open WebUI al servidor de LM Studio:
- En Open WebUI, ve a Settings (icono de engranaje) → Admin Settings
- En Model Providers, haz click en OpenAI
- En Base URL, escribe:
http://localhost:1234/v1 - En API Key, escribe cualquier valor (LM Studio no requiere autenticacion local, pero el campo es obligatorio) — usa
lmstudio - Haz click en Save
Ve a la lista de modelos (icono de modelo en la barra superior) y haz click en Refresh Models. Deberías ver el modelo que cargaste en LM Studio.
3 Personalizar Open WebUI
Open WebUI tiene opciones de configuración que mejoran significativamente la experiencia. Ajustemos las mas importantes:
Configuración del modelo por defecto
- Ve a Settings → Default Models
- Selecciona tu modelo como predeterminado para Chat
Parámetros de generación
En Settings → Advanced, ajusta estos parametros:
| Parametro | Valor recomendado | Que hace |
|---|---|---|
| Temperature | 0.7 | Creatividad. 0.3 = mas determinista, 1.0 = mas creativo |
| Max Tokens | 4096 | Longitud maxima de la respuesta |
| Top P | 0.9 | Nucleo de muestreo. 0.9 es un buen equilibrio |
| Context Length | 8192 | Tamano de ventana de contexto (mas = mas memoria usada) |
4 Añadir búsqueda web con SearXNG
Los modelos locales tienen conocimiento limitado a su fecha de entrenamiento. Para que tu chat pueda buscar información actual, conectamos SearXNG como motor de búsqueda web.
Que es SearXNG
SearXNG es un motor de búsqueda metasearch de código abierto que agrega resultados de multiples fuentes (Google, Bing, DuckDuckGo, Wikipedia) sin rastrear tu actividad. Corre en tu propia máquina y no requiere cuenta ni API key.
Instalación de SearXNG
Usamos Docker Compose para una instalación limpia:
# Crear un directorio para SearXNG
mkdir searxng
cd searxng
# Descargar los archivos de configuracion oficial
curl -fsSLO https://raw.githubusercontent.com/searxng/searxng/master/container/docker-compose.yml
curl -fsSLO https://raw.githubusercontent.com/searxng/searxng/master/container/.env.example
# Copiar y editar la configuración
cp .env.example .env
# Iniciar SearXNG
docker compose up -dSearXNG estará disponible en http://localhost:8080.

Conectar SearXNG a Open WebUI
Open WebUI tiene soporte nativo para búsqueda web integrada:
- En Open WebUI, ve a Settings → Admin Settings → Features
- Activa Web Search
- En SearXNG URL, escribe:
http://searxng-web:8080/search?q=&format=json - Haz click en Save
- Verifica que en el archivo settings.yml de searxng tengas en la sección de search:
formats:
- html
- jsonhttp://searxng-web:8080. Si SearXNG corre fuera de Docker, usa http://localhost:8080.Ahora, cuando hagas una pregunta en Open WebUI, el modelo podra buscar información actual en la web antes de responder.
Troubleshooting: Problemas comunes y soluciones
Si algo no funciona como esperabas, revisa estos problemas frecuentes. La mayoría tienen solución rápida.
Open WebUI no puede conectar a LM Studio
El error mas común es «Connection refused» o «Failed to fetch models» en Open WebUI.
Solución:
- Verifica que el servidor de LM Studio este activo (veras un check verde en el panel de Server)
- Confirma que la URL en Open WebUI sea exactamente
http://localhost:1234/v1— sin barra final, sin typo - Prueba desde terminal:
curl http://localhost:1234/v1/models. Si responde con una lista de modelos, la conexión funciona - Si usas Linux, asegúrate de que no haya un firewall bloqueando el puerto 1234
El modelo no cabe en la GPU (error de memoria / OOM)
Si ves mensajes como «Out of memory» o el modelo carga pero la generación es extremadamente lenta, el modelo es demasiado grande para tu VRAM.
Solución:
- Descarga una versión mas pequeña del mismo modelo (cambia de Q8 a Q4_K_M o Q3_K_M )
- Elige un modelo con menos parámetros (de 27B a 9B, por ejemplo)
- Reduce el Context Length en LM Studio a 4096 o menos — cada token de contexto consume VRAM
- En LM Studio, ve al panel de Server y verifica cuantos GB de VRAM se están usando
- Intenta utilizar algo de offload a RAM (ralentizara la inferencia pero en modelos MoE puede ser una pérdida de rendimiento aceptable)
La generación es muy lenta (menos de 10 tokens por segundo)
Si la velocidad es baja, puede deberse a varias causas:
Solución:
- Verifica que el modelo este cargado en la GPU y no solo en CPU — en LM Studio, el panel de Server muestra «GPU offload». Deberia estar cerca del 100%
- Cierra otras aplicaciones que usen la GPU (navegador con muchas pestañas, juegos, editores de video)
- Reduce el Context Length — un contexto de 16K consume significativamente mas VRAM y ancho de banda
- Si usas Windows, verifica que los drivers de NVIDIA estén actualizados
SearXNG devuelve resultados vacíos o sin contenido
Es común que SearXNG devuelva resultados pero sin texto util, o que las respuestas del modelo digan «no encontré información» aunque la búsqueda se haya ejecutado.
Causas y soluciones:
- Motor de búsqueda desactivado: SearXNG viene con algunos motores desactivados por defecto. Edita el archivo
settings.ymldel contenedor y activa mas motores en la secciónengines. Reinicia el contenedor despues:docker compose restart - Rate limiting de fuentes: Si haces muchas búsquedas rápidas, Google/Bing pueden bloquear temporalmente. Espera unos minutos o reduce la frecuencia de búsquedas.
- Formato de respuesta: Verifica que la URL de busqueda incluya
&format=jsonal final. Sin esto, SearXNG devuelve HTML en lugar de JSON y Open WebUI no puede procesarlo. - Prueba la API: Ejecuta
curl "http://localhost:8080/search?q=internet&format=json"y revisa que el JSON devuelto tenga un arrayresultscon contenido
SearXNG no busca nada (Open WebUI no activa la búsqueda web)
A veces el modelo simplemente ignora la herramienta de búsqueda web y responde solo con su conocimiento interno.
Causas y soluciones:
- El modelo no esta configurado para usar herramientas: No todos los modelos soportan function calling. Modelos como Qwen3.6 27B y 35B lo soportan bien. Modelos mas pequeños pueden ignorar las herramientas
- Web Search desactivada en Open WebUI: Ve a Settings → Admin Settings → Features y verifica que «Web Search» este activada
- No se generó ninguna consulta de búsqueda: Verifica que la longitud de contexto no sea demasiado baja.
- La búsqueda no devuelve resultados: Es posible que algunos sitios web estén bloqueando el acceso a herramientas automatizadas (bots o scrapers), por lo que quizá necesites usar soluciones especializadas de scraping, como Firecrawl
SearXNG falla con error de red desde Open WebUI
Si ambos corren en Docker pero Open WebUI no puede alcanzar SearXNG:
Solución:
- Si usan el mismo docker-compose.yml, la URL es
http://searxng-web:8080(nombre del servicio) - Si estan en networks diferentes, conecta ambos a la misma red:
docker network connect red_compartida searxng-web - Si SearXNG corre fuera de Docker (en el host), usa
http://host.docker.internal:8080en macOS/Windows ohttp://172.17.0.1:8080en Linux
Docker da error de permisos o el contenedor no arranca
En Linux, es comun recibir «permission denied» al ejecutar comandos de Docker.
Solución:
- Agrega tu usuario al grupo docker:
sudo usermod -aG docker $USERy reinicia la sesión - Si el contenedor falla al iniciar, revisa los logs:
docker logs open-webui - Si hay conflicto de puerto 3000, cambia el mapeo:
-p 3001:8080en lugar de-p 3000:8080
Tu setup ya funciona — ¿Qué sigue?
Ya tienes un sistema de IA local completo: motor de inferencia (LM Studio), interfaz de chat (Open WebUI) y búsqueda web (SearXNG). A partir de aquí, puedes profundizar en varias direcciones:
- Agentes autónomos: Configurar tu modelo para que ejecute acciones autónomas — buscar información, escribir código, interactuar con APIs.
- Multi-GPU: Distribuir modelos grandes entre varias GPUs para correr modelos de 70B+ parámetros.
- Fine-tuning básico: Entrenar tu propio modelo con datos especificos para tu dominio.
- Hardware alternativo: Configurar IA local en Mac M-series con Apple Silicon, o en servidores con GPUs AMD.
Preguntas frecuentes
¿Cuanta VRAM necesito para IA local en 2026?
Mínimo 8 GB de VRAM (RTX 4060 o equivalente) para modelos de 9B parametros. Con 16 GB (RTX 5070 Ti) puedes correr modelos de 27B. Con 32 GB (RTX 5090) llegas a modelos de 27B fp8 o 35b MoE. Sin GPU dedicada, la velocidad con CPU sola será de 5-10 tokens por segundo — prácticamente inutilizable para conversaciones fluidas.
¿Funciona la IA local sin internet?
Sí. Una vez descargado el modelo, LM Studio y Open WebUI funcionan completamente offline. La única conexión necesaria es para descargar los modelos la primera vez y para la búsqueda web con SearXNG.
¿Es legal usar modelos open source localmente?
Sí. Modelos como Qwen3.6 (licencia Apache 2.0), Gemma 4 (licencia de Google) y Nemotron 4B (licencia de NVIDIA) permiten uso personal y comercial local. Cada modelo tiene su licencia específica — revísala antes de usarlo en producción.
¿Puedo usar IA local para trabajo profesional?
Sí, con salvedades. Los modelos locales de 27B-35B parámetros son competitivos para redacción, análisis de código y resumen de documentos. Para tareas críticas (medico, legal), siempre verifica las respuestas. No tienen el mismo nivel de razonamiento que GPT-5.5 o Claude Opus 4.7.
¿Cuanto espacio en disco necesito?
Cada modelo en formato GGUF ocupa entre 5 GB (modelos de 9B en Q4) y 25 GB (modelos de 35B en Q4). Con 3-4 modelos necesitas 100 GB libres como mínimo. Un SSD NVMe es imprescindible para tiempos de carga mas rápidos.
¿Puedo cambiar de modelo sobre la marcha?
Si. En LM Studio, ve al panel de Server, selecciona otro modelo y haz click en «Reload». Open WebUI detectara automáticamente el nuevo modelo en la siguiente actualización de la lista.