
El problema: Modelos desconectados del mundo
Un LLM es un generador de texto. Su conocimiento es estático, limitado a los datos de entrenamiento, y no tiene forma de interactuar con sistemas externos. No puede consultar una base de datos, llamar a una API, ejecutar código, ni acceder a información en tiempo real.
Esto lo convierte en un sistema pasivo, responde, pero no actúa. Para tareas que requieren datos frescos, acceso a información privada, o interacción con otros sistemas, el modelo por sí solo es insuficiente.
Tool Use cierra esa brecha, permite que el modelo decida cuándo necesita interactuar con el mundo exterior, qué herramienta usar, y con qué parámetros. Transforma al LLM de un respondedor pasivo en un sistema activo que percibe, razona y actúa.
Pero no es tan simple como «conectar herramientas». La decisión de qué herramientas exponer, cómo describirlas, y cómo manejar sus fallos define si el agente funciona o se rompe en producción.
El ciclo de Tool Use
El patrón sigue seis etapas:
- Definición de herramientas: las funciones externas se definen con nombre, descripción, tipos de parámetro y metadatos visibles para el LLM.
- Decisión del LLM: el modelo evalúa la petición del usuario y decide si necesita llamar a una herramienta.
- Generación de la llamada: el LLM produce un output estructurado (JSON) especificando el nombre de la herramienta y los argumentos.
- Ejecución: la capa de orquestación intercepta la llamada, ejecuta la función real, y captura el resultado.
- Observación: el resultado de la herramienta se devuelve al agente.
- Procesamiento: el modelo incorpora el resultado en su respuesta o decide el siguiente paso (otra llamada, reflection, o respuesta final).
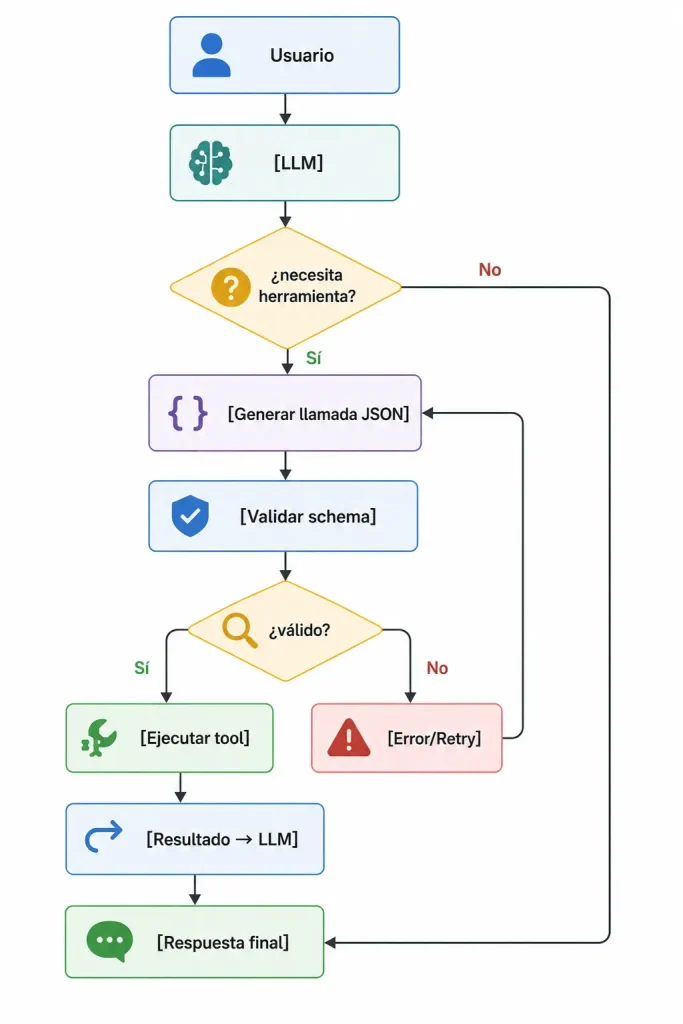
Nota que la validación del schema aparece entre la generación y la ejecución. Sin ella, una llamada alucinada se traduce en un error de runtime. Con ella, el agente puede recuperar o pedir aclaración antes de ejecutar algo inválido.
Function Calling vs Tool Use
Son términos que se usan como sinónimos, pero no lo son.
Function Calling es el mecanismo técnico: el LLM genera un objeto JSON con el nombre de la función y sus argumentos. Es lo que OpenAI llamó «function calling» en su API original, y lo que Anthropic llama «tool use». Es el canal de comunicación entre el modelo y el sistema externo.
Tool Use es el concepto más amplio. Una «herramienta» puede ser:
- Una función Python local.
- Un endpoint REST de una API externa.
- Una consulta a una base de datos.
- Un executor de código en sandbox.
- Otro agente especializado (Agent-as-Tool).
La distinción importa: afecta cómo diseñas el sistema — y las consecuencias de hacerlo mal son errores silenciosos que el usuario interpreta como respuestas correctas. Si solo usas funciones locales, el riesgo es bajo. Si expones APIs externas o executores de código, el riesgo crece y necesitas capas de validación y seguridad adicionales.
Ejemplo: herramienta básica con LangChain
from langchain_core.tools import tool
@tool
def buscar_clima(ciudad: str) -> str:
"""Obtiene el clima actual de una ciudad.
Usa esta herramienta cuando el usuario pregunta por el tiempo,
temperatura o condiciones atmosféricas de un lugar específico.
Args:
ciudad: nombre de la ciudad en español o inglés.
"""
# En producción: llamada a API real (OpenWeather, etc.)
datos = {
"madrid": "Soleado, 28C",
"london": "Nublado, 15C",
"tokyo": "Lluvioso, 22C",
}
return datos.get(ciudad.lower(), f"Sin datos para: {ciudad}")
@tool
def calcular_expresion(expresion: str) -> str:
"""Evalúa una expresión matemática y devuelve el resultado.
Usa esta herramienta para cálculos precisos: aritmética,
conversiones de unidades, operaciones financieras.
Args:
expresion: expresión matemática en formato Python (ej: "2 + 2 * 3").
"""
try:
resultado = eval(expresion, {"__builtins__": {}}, {})
return str(resultado)
except Exception as e:
return f"Error: {e}"Nota la estructura de los docstrings: descripción clara del propósito, cuándo usar la herramienta, y documentación de los parámetros. El LLM decide qué herramienta llamar basándose exclusivamente en estos docstrings. Descripciones vagas producen llamadas incorrectas.
Definición de herramientas: el arte invisible
La parte más subestimada de Tool Use es la definición de las herramientas. El LLM no ve el código. Ve la descripción. Si la descripción es ambigua, el modelo elige mal.
Esto es lo que vimos en producción: teníamos dos herramientas de búsqueda con descripciones similares («buscar información» y «buscar datos»). El modelo las confundía constantemente, llamando a la herramienta de información general cuando necesitaba datos estructurados, y viceversa. El resultado: outputs incorrectos que el agente presentaba como ciertos.
Lo que funcionó: renombres explícitos y descripciones que dejaban claro el caso de uso de cada una. «buscar_información_general» para consultas abiertas. «consultar_base_datos» para datos estructurados con schema conocido. La diferencia no estaba en el código, estaba en la descripción.
Y esto no fue el único problema. Hubo una herramienta de cálculo financiero que el modelo usaba para todo: conversiones de moneda, intereses, incluso para pedir «cuánto es 15% de 250». El problema era que la herramienta usaba eval() para los cálculos, y en producción recibimos peticiones como «evalúa 1/0» o «calcula len(‘hola’)». No era malicia, era el modelo explorando los límites de la herramienta. Lo que hicimos: restringir eval() a operaciones aritméticas básicas y añadir una lista blanca de funciones permitidas. Funcionó, pero fue una corrección que deberíamos haber hecho antes de deployar.
Reglas para descripciones efectivas
- El nombre de la herramienta debe ser descriptivo y único.
buscares ambiguo.buscar_productos_inventarioes claro. - La descripción debe incluir el propósito, los casos de uso, y los parámetros.
- Especifica cuándo NO usar la herramienta. «No usar para consultas históricas» evita llamadas innecesarias.
- Si una herramienta requiere permisos o tiene límites, menciónalo en la descripción.
El agente en acción
Con las herramientas definidas, el agente necesita un executor que maneje el ciclo completo: decisión del LLM, ejecución de la herramienta, retorno del resultado, y procesamiento final.
Ejemplo: agente con Tool Use completo
from langchain_core.prompts import ChatPromptTemplate
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Herramientas definidas previamente
tools = [buscar_clima, calcular_expresion]
# Prompt con placeholder para el historial de tool calls
prompt = ChatPromptTemplate.from_messages([
("system", "Eres un asistente técnico. Usa las herramientas disponibles cuando sea necesario."),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
# Crear el agente
agent = create_tool_calling_agent(llm, tools, prompt)
# Executor con manejo de errores
executor = AgentExecutor(
agent=agent,
tools=tools,
handle_parsing_errors=True,
max_iterations=10,
verbose=True,
)
# Ejecutar
resultado = executor.invoke({"input": "¿Cuál es el clima en Madrid y cuánto es 15% de 250?"})El agent_scratchpad es donde el agente registra cada paso: qué herramienta llamó, qué resultado obtuvo, y qué decisión tomó a continuación. Sin este historial, el modelo pierde el contexto de sus propias acciones y puede repetir llamadas o entrar en bucles.
El max_iterations=10 es un límite de seguridad. Sin él, un agente que no converge puede seguir llamando herramientas indefinidamente hasta agotar el contexto o el rate limit.
Validación de llamadas: la capa que todos olvidan
El LLM puede alucinar el nombre de una herramienta, inventar parámetros, o pasar tipos incorrectos. En el 5-10% de los casos con descripciones ambiguas, esto ocurre en producción.
La solución es una capa de validación entre la generación de la llamada y su ejecución:
import json
import inspect
from pydantic import BaseModel, ValidationError
class ToolCall(BaseModel):
name: str
arguments: dict
# Registry de herramientas válidas
TOOL_REGISTRY = {t.name: t for t in tools}
def validate_tool_call(call_json: str) -> ToolCall:
"""Valida que la llamada del LLM sea correcta antes de ejecutarla."""
try:
data = json.loads(call_json)
call = ToolCall(**data)
# Verificar que la herramienta existe
if call.name not in TOOL_REGISTRY:
raise ValueError(f"Herramienta desconocida: {call.name}")
# Verificar schema de parámetros
tool_fn = TOOL_REGISTRY[call.name].func
sig_params = list(inspect.signature(tool_fn).parameters.keys())
extra = set(call.arguments.keys()) - set(sig_params)
if extra:
raise ValueError(f"Parámetros inválidos: {extra}")
return call
except (json.JSONDecodeError, ValidationError, ValueError) as e:
return None # Llamar a fallbackSin validación, una llamada alucinada se traduce en un error de runtime que el agente tiene que manejar. Con validación, el error se detecta antes de ejecutar y puedes pedir al modelo que intente de nuevo con la información correcta.
Errores en herramientas: cómo manejarlos
Las herramientas fallan. Una API externa tiene timeout, una base de datos devuelve un error de conexión, un cálculo lanza una excepción. La pregunta no es si fallan, es cómo el agente reacciona.
Lo que no funciona: devolver el stack trace al usuario. Lo que tampoco funciona: ignorar el error y continuar como si nada pasara.
Lo que funciona es una estrategia de tres niveles:
- Reintento con backoff: para errores transitorios (timeout, rate limit), reintenta con delay exponencial. Un timeout de 3 segundos no es un fallo permanente.
- Fallback a herramienta alternativa: si la herramienta principal falla, usa una alternativa. Si «consultar_base_datos» falla, «buscar_información_general» puede ser un fallback aceptable.
- Comunicación clara al usuario: si nada funciona, el agente debe comunicar el fallo de forma útil. «No pude consultar el clima actual. Intenta de nuevo en unos minutos» es mejor que «Error 500: Internal Server Error».
En un sistema real, vimos que el 80% de los fallos de herramientas eran transitorios. Un reintento simple resolvía la mayoría. El 20% restante eran errores de datos (registro no encontrado, parámetro inválido) que requerían que el agente pidiera aclaración al usuario.
Cuándo Tool Use NO es la respuesta
Tool Use añade latencia y complejidad. Cada llamada a herramienta es una llamada adicional al modelo más la ejecución de la función. No todo requiere una herramienta.
Ejemplos donde Tool Use sobra:
- Preguntas de conocimiento general que el modelo ya sabe responder.
- Cálculos simples que el modelo puede hacer directamente (2 + 2, conversiones básicas).
- Generación de contenido creativo donde no se necesitan datos externos.
La prueba es simple: ejecuta la petición sin herramientas y mide la tasa de errores. Si el modelo responde correctamente la mayoría de las veces, las herramientas son overhead innecesario.
Tool Use y los demás patrones
Tool Use se combina con casi todos los demás patrones. La combinación más común es Planning → Tool Use: el agente genera un plan, y cada paso del plan puede invocar herramientas diferentes.
Con Reflection, la combinación es poderosa: el agente usa herramientas para recopilar datos, y un Critic revisa si los datos son suficientes y correctos antes de generar la respuesta final.
Con Routing, el router decide si una petición necesita herramientas o puede responderse directamente. Peticiones simples van al modelo directo. Peticiones complejas van al agente con herramientas.
Con Parallelization, múltiples herramientas pueden ejecutarse concurrentemente. Si un agente necesita consultar clima, tráfico y eventos para responder una pregunta de viaje, las tres llamadas pueden correr en paralelo en lugar de secuencialmente.
Observabilidad
Un agente con herramientas sin métricas es una caja negra. Estos son los indicadores mínimos:
- Tasa de tool calls por petición: cuántas herramientas se llaman en promedio. Si crece sin razón, el agente puede estar perdido.
- Tiempo de ejecución por herramienta: identifica cuellos de botella. Una herramienta que tarda 10 segundos domina la latencia total.
- Tasa de error por herramienta: si una herramienta falla más del 5% de las veces, necesita revisión.
- Validaciones rechazadas: cuántas llamadas del LLM fallan la validación de schema. Si supera el 10%, las descripciones de herramientas necesitan mejora.
Un log estructurado con {tool_name, arguments, result_type, duration_ms, error} es suficiente para mantener el sistema bajo control.
Anti-patrones
- Descripciones vagas: si el LLM no entiende qué hace una herramienta desde su docstring, la llamará incorrectamente. «buscar» es ambiguo. «buscar_productos_inventario» es claro.
- Demasiadas herramientas simultáneas: presentar 50+ herramientas al LLM aumenta la probabilidad de selecciones incorrectas. Agrupa por dominio o usa routing para seleccionar el subconjunto relevante.
- Sin manejo de errores: cuando una herramienta falla, el agente necesita señales claras para recuperarse. Excepciones sin contexto producen respuestas confusas.
- Devolver errores crudos al usuario: los fallos de herramientas deben ser capturados y reformulados por el agente, no filtrados como stack traces.
- Ignorar la validación: el LLM puede alucinar nombres de herramientas o valores de parámetro. Validar antes de ejecutar evita errores de runtime.
- Usar Tool Use para todo: si el modelo ya sabe la respuesta, añadir una llamada a herramienta desperdicia tiempo y tokens.
¿Qué es Function Calling?
Es el mecanismo técnico donde el LLM genera una petición estructurada (JSON) para invocar una función externa. El modelo decide si necesita usar una herramienta, qué herramienta usar, y con qué parámetros.
¿Cuál es la diferencia entre Tool Use y Function Calling?
Function Calling es el mecanismo técnico (generación de JSON estructurado). Tool Use es el concepto más amplio: incluye funciones, APIs, bases de datos, y hasta otros agentes como herramientas.
¿Cuántas herramientas puedo darle a un agente?
La mayoría de modelos empiezan a confundirse con más de 10-15 herramientas simultáneas. Si necesitas más, agrúpalas por dominio o usa un router que seleccione el subconjunto relevante antes de pasarlas al agente.
¿Qué pasa si el modelo alucina el nombre de una herramienta?
Ocurre en el 5-10% de los casos con descripciones vagas. La solución es validar la llamada antes de ejecutarla: verificar que el nombre exista, que los parámetros cumplan el schema, y tener un fallback para llamadas inválidas.
¿Tool Use funciona con modelos locales?
Sí, pero depende del modelo. Los modelos de 7B suelen tener dificultades con schemas complejos. Los de 13B+ manejan bien herramientas simples. Los de 30B+ se acercan al rendimiento de modelos comerciales.
¿Cómo evito que un agente entre en bucle llamando herramientas?
Limita el máximo de tool calls por petición (5-10 es razonable). Registra las herramientas ya llamadas para detectar repeticiones. Si el modelo llama a la misma herramienta con los mismos argumentos dos veces, corta el bucle.
Cierre
Tool Use es lo que convierte a un LLM de un chatbot en un agente. Sin herramientas, el modelo está limitado a lo que sabe. Con herramientas, puede interactuar con el mundo real.
Pero cada herramienta que añades es una decisión de diseño con consecuencias. Las herramientas mal definidas producen llamadas incorrectas. Las llamadas incorrectas producen outputs erróneos. Los outputs erróneos erosionan la confianza del usuario, y recuperar esa confianza es más caro que escribir una buena descripción desde el principio.
El sistema que funciona no es el que tiene más herramientas. Es el que tiene las herramientas correctas, bien descritas, y con manejo de errores que no se rompa cuando algo falla. Todo lo demás es deuda técnica que el modelo pagará con intereses.