
El problema que Routing resuelve
Un pipeline lineal funciona bien cuando sabes qué va a pasar:
Entrada → paso 1 → paso 2 → salida. Predecible, fácil de testear, barato de mantener.
La realidad es que los inputs de un sistema con LLMs rara vez siguen un guion. En un chatbot de soporte, un usuario puede preguntar por el estado de un pedido, pedir cancelar una suscripción, o simplemente insultar al bot. Un pipeline lineal procesa los tres casos igual y produce resultados mediocres o directamente erróneos.
Routing es la respuesta. Introduce lógica condicional en el flujo del agente: evalúa el input, clasifica la intención, y dirige la ejecución al handler correcto. No es un reemplazo de Prompt Chaining, es su complemento. Chaining maneja el qué hacer dentro de un flujo; Routing decide cuál flujo activar.
Arquitectura básica
El patrón tiene tres componentes:
- Router: El punto de decisión. Recibe el input y produce una clasificación.
- Handlers: Los flujos especializados. Cada uno maneja un tipo de input específico.
- Fallback: La ruta por defecto. Maneja lo que el router no clasificó.
La estructura es esencialmente un switch-case, pero en lugar de reglas estáticas, la decisión puede tomarla un modelo de lenguaje, un clasificador ML, o lógica determinista.
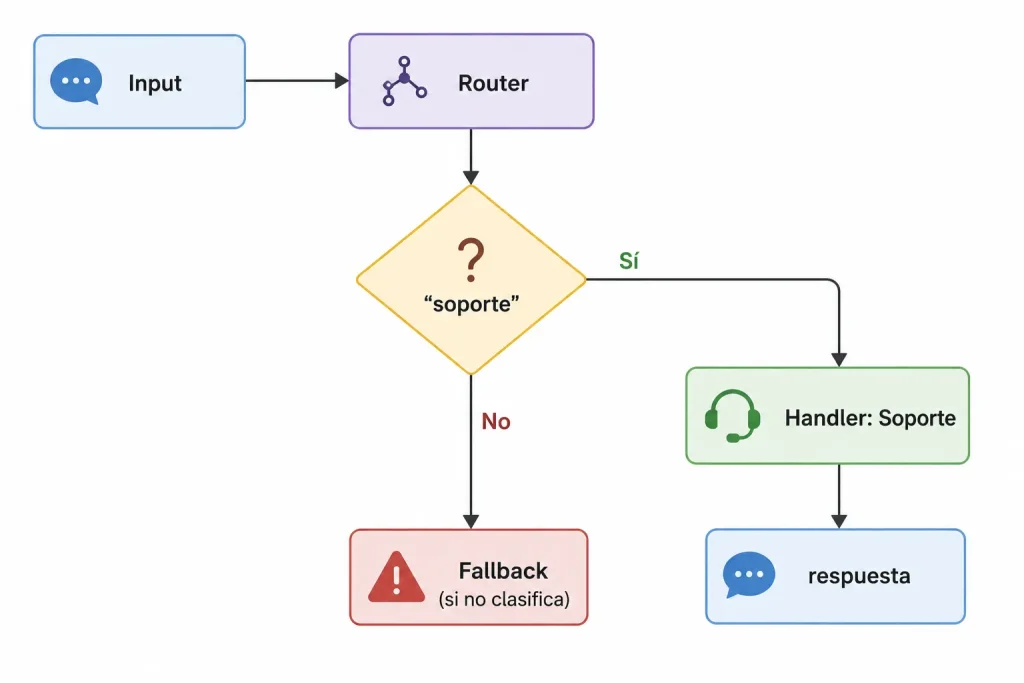
El router puede estar en la entrada del sistema, clasificando la solicitud primaria, o en cualquier punto intermedio. De hecho, uno de los usos más efectivos es el mid-chain routing: un pipeline avanza normalmente hasta que un resultado intermedio requiere una decisión. Por ejemplo, un sistema de análisis financiero extrae datos, y dependiendo de si detecta anomalías, deriva a un flujo de alerta o a uno de reporte estándar.
Ejemplo: estructura de un router
Un router funcional en Python se reduce a esto:
class Router:
def __init__(self, llm_router, rule_patterns, handlers):
self.llm_router = llm_router
self.rule_patterns = rule_patterns # [(regex, categoria), ...]
self.handlers = handlers # {categoria: handler_func}
def classify(self, input_text: str) -> str:
# 1. Intenta rule-based primero
for pattern, category in self.rule_patterns:
if pattern.search(input_text):
return category
# 2. Fallback a LLM-based
return self.llm_router.route(input_text)
def execute(self, input_text: str) -> str:
category = self.classify(input_text)
handler = self.handlers.get(category, self.handlers["default"])
return handler(input_text)Tres capas: regla rápida, LLM como red de seguridad, fallback como último recurso. Es el patrón que más se repite en producción porque suele resolver la mayoría de los casos sin costo de tokens y deja que el modelo maneje lo impredecible.
Los cuatro métodos de routing
En la literatura sobre sistemas LLM, suelen distinguirse cuatro mecanismos principales de routing. Cada uno tiene un perfil de latencia, costo y precisión distinto. Elegir mal aquí no rompe el sistema, lo hace ineficiente.
LLM-based routing
El modelo mismo clasifica el input mediante un prompt estructurado y devuelve una etiqueta. Es el más flexible: entiende contexto, intención implícita, y generaliza a inputs no vistos.
El problema es que cuesta. Cada decisión de routing es una llamada completa al modelo. En sistemas de alto volumen, eso se acumula rápido. La mitigación estándar es usar un modelo pequeño y rápido exclusivamente para el router (un modelo de 1-3B parámetros suele ser suficiente para clasificación de intención). No necesitas GPT-5 para decidir si algo es una queja o una consulta.
En LangChain se implementa con RunnableBranch. En LangGraph, las aristas condicionales del grafo son esencialmente routing basado en estado.
from langchain.chat_models import init_chat_model
from langchain_core.runnables import RunnableBranch
model = init_chat_model("qwen2.5-3b", provider="ollama")
router = RunnableBranch(
(
lambda x: "precio" in x["input"].lower() or "costo" in x["input"].lower(),
lambda x: f"Consultando precios: {x['input']}", # handler precios
),
(
lambda x: "soporte" in x["input"].lower() or "problema" in x["input"].lower(),
lambda x: f"Derivando a soporte: {x['input']}", # handler soporte
),
# Fallback: LLM clasifica lo que las reglas no atraparon
model.bind(
response_format={"type": "json_schema", "json_schema": {...}}
).pipe(lambda x: x.json()["categoria"]),
)
result = router.invoke({"input": "Mi suscripción no funciona"})Nótese que las ramas con lambda son reglas simples, solo la rama por defecto llama al modelo. Eso ya es el patrón híbrido en practica: rule-based como filtro, LLM como catch-all.
Embedding-based routing
El input se vectoriza y se compara contra embeddings pre-calculados de cada ruta. La ruta con mayor similitud semántica gana.
Esto funciona bien cuando las rutas son estables y conocidas de antemano. Si tienes 5 categorías de soporte, calculas sus embeddings una vez y el routing se reduce a una operación de similitud coseno, básicamente instantánea y gratuita.
El problema aparece cuando las categorías son semánticamente cercanas o ambiguas. «Mi cuenta está bloqueada» vs «no puedo iniciar sesión», dos frases que comparten contexto pero requieren acciones distintas. La similitud coseno tiende a confundirlas; un LLM-based router distingue mejor los matices porque entiende intención, no solo proximidad vectorial.
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Embeddings pre-calculados de cada ruta
route_embeddings = {
"precios": embed("precios, tarifas, planes, costo, factura"),
"soporte": embed("error, problema, no funciona, ayuda, bug"),
"ventas": embed("demo, prueba, comprar, contactar, empresa"),
}
def route_by_embedding(input_text: str) -> str:
input_vec = embed(input_text)
scores = {
route: cosine_similarity(input_vec, vec)
for route, vec in route_embeddings.items()
}
return max(scores, key=scores.get)La funcion embed puede ser cualquier modelo de embeddings, sentence-transformers, Ollama con nomic-embed, o incluso el API de OpenAI. Una vez calculados los embeddings de las rutas, el routing en si no requiere llamadas al modelo.
Rule-based routing
if/else, regex, match de keywords. Determinista, rápido, barato.
Y frágil. Un input que no coincide con ninguna regla cae al fallback. Si las reglas son exhaustivas, funciona perfecto pero «exhaustivo» es una palabra peligrosa en producción. Los usuarios siempre encuentran formas de preguntar que no anticipaste.
El uso correcto de rule-based routing no es como mecanismo principal, sino como primer filtro. Intercepta los casos obvios; «precio», «factura», «contrato» y deja que el LLM-based router maneje lo que sobra. Esa combinación reduce el costo total significativamente.
import re
RULES = [
(re.compile(r"\b(precio|costo|tarifa|factura|cobro)\b", re.I), "precios"),
(re.compile(r"\b(error|problema|falla|no funciona|bug)\b", re.I), "soporte"),
(re.compile(r"\b(demo|prueba gratuita|empresa|contactar)\b", re.I), "ventas"),
(re.compile(r"\b(hola|buenos d[íi]as|saludos)\b", re.I), "saludo"),
]
def rule_route(text: str) -> str | None:
for pattern, category in RULES:
if pattern.search(text):
return category
return None # fallback necesario
result = rule_route("Tengo un error con mi factura") # → "soporte"ML model-based routing
Un clasificador discriminativo fine-tuned toma la decisión. No genera texto, evalúa parámetros y devuelve una categoría. Es más barato que llamar a un LLM general-purpose y más preciso que embeddings simples.
Pero requiere datos de entrenamiento y mantenimiento. Si las categorías de routing cambian con frecuencia, algo común en productos en crecimiento, fine-tunar un clasificador cada vez que añades una ruta se vuelve costoso en ingeniería. Tiene más sentido en sistemas maduros donde el espacio de clasificación es estable.
Comparativa
| Método | Latencia | Costo | Precisión | Flexibilidad | Mantenimiento |
|---|---|---|---|---|---|
| LLM-based | Media-Alta | Alto (tokens) | Alta-Muy alta | Muy alta | Bajo (cambiar prompt) |
| Embedding-based | Baja | Bajo | Media | Media | Medio (recalcular embeddings) |
| Rule-based | Mínima | Cero | Muy alta (casos previstos) | Baja | Alto (mantener reglas) |
| ML model-based | Baja | Medio (fine-tuning) | Alta | Media-Alta | Alto (reentrenar) |
Routing en la práctica: dónde colocarlo
La posición del router en el flujo determina qué tipo de decisión toma. Hay tres ubicaciones comunes:
- Entry-point routing: Clasifica la solicitud del usuario antes de cualquier procesamiento. Es el patrón más visible: un chatbot que deriva entre «ventas», «soporte» y «técnico» desde el primer mensaje.
- Mid-chain routing: Aparece después de uno o más pasos de procesamiento. Un pipeline de análisis primero extrae datos, y dependiendo de lo que encuentre, activa rutas distintas. Aquí es donde Routing gana sobre Chaining puro: el pipeline se adapta a los datos en lugar de seguir un guion fijo.
- Subroutine routing: Elige entre herramientas o sub-agentes. Function calling puede verse como una forma de subroutine routing donde el modelo selecciona una herramienta específica. La diferencia con Routing como patrón es que subroutine routing suele ser una decisión puntual dentro de un flujo mayor, no el mecanismo principal de decisión.
He visto sistemas que ponen routing en las tres capas simultáneamente, entry-point para la intención general, mid-chain para decisiones basadas en datos, y subroutine para selección de herramientas. Funciona, pero cada capa añade latencia. En producción, el overhead de tres decisiones secuenciales puede superar el beneficio de la especialización.
Cómo medir si tu routing funciona
Un router en producción sin métricas es una caja negra. No sabes si está tomando las decisiones correctas hasta que un usuario se queja. Estos son los indicadores mínimos:
- Porcentaje de requests por ruta: La distribución te dice si las categorías están equilibradas. Si el 70% de todo el tráfico cae en una sola ruta, probablemente estás subutilizando los handlers especializados o las descripciones de ruta están mal definidas.
- Tasa de fallback: El porcentaje de inputs que el router no clasificó. Como regla práctica, una tasa de fallback persistentemente alta suele indicar que las categorías o reglas necesitan revisión. Si el fallback crece con el tiempo, el espacio de clasificación está cambiando y no lo estás siguiendo.
- Confianza media del router: En embedding-based, la puntuación de similitud coseno. Cuando el proveedor lo expone, los log-probs de la etiqueta elegida o alguna puntuación de confianza derivada del modelo. Una confianza media baja significa que el router opera en zona gris, clasifica, pero inseguro. Es señal de que las rutas necesitan redefinición.
- Rutas más confundidas: Cuando dos categorías compiten consistentemente por el mismo input, las descripciones de ruta se superponen. Revisar los pares de rutas con mayor tasa de clasificación incorrecta (si tienes ground truth) es la forma más directa de encontrar ambigüedades.
- Coste por decisión: En un router híbrido, esto te dice cuántos requests alcanzaron la capa LLM. Si el rule-based filtro intercepta el 80%, el coste real es una fracción del peor caso. Monitorear esto con el tiempo detecta si la distribución de inputs está cambiando.
No necesitas un dashboard completo. Un log estructurado con {input_hash, ruta, metodo, confianza, timestamp} y un resumen diario es suficiente para mantener el router bajo control. Lo que importa es detectar la deriva antes de que se convierta en un problema visible para el usuario.
Anti-patrones que rompen el routing
Los errores aquí no son técnicos, son de diseño. El código de routing rara vez falla; falla la decisión de qué enrutar y cuándo.
- Todo por un agente monolítico: Si un solo agente maneja reservas, consultas, quejas y debugging, el contexto se contamina y el modelo produce resultados mediocres en todo. Routing existe para evitar esto.
- Sin fallback: Inputs no clasificados causan fallos silenciosos o respuestas genéricas que frustran al usuario. La ruta por defecto no es opcional.
- Rutas superpuestas: Si dos rutas describen «soporte técnico» y «problemas con el producto», el router oscila entre ellas. Las descripciones de ruta deben ser mutuamente excluyentes.
- Over-routing: Añadir capas de routing donde un pipeline lineal resuelve el problema. Cada decisión de routing añade latencia. Si el flujo es predecible, Chaining es más barato y más rápido.
Cuándo NO usar Routing
Routing es solución a un problema específico: inputs impredecibles que requieren flujos distintos. Si tu sistema procesa un tipo conocido de input en una secuencia fija, Routing añade complejidad sin retorno.
Ejemplos concretos donde Routing sobra:
- Un pipeline de extracción de datos de PDFs siempre sigue los mismos pasos.
- Un sistema que genera resúmenes desde texto, no necesita decidir entre flujos.
- Un classificador binario (spam/no spam), es routing de dos ramas, pero un modelo directo es más eficiente que un router + dos handlers.
La regla práctica: si puedes describir el flujo como «siempre haz A, luego B, luego C», no necesitas Routing. Úsalo cuando la pregunta real es «¿cuál de estos caminos tomar?».
Routing y Prompt Chaining: no son rivales
El primer artículo de esta serie cubrió Prompt Chaining. Routing no lo reemplaza, lo complementa. De hecho, la combinación más común en producción es:
Routing → Prompt Chaining
El router decide el flujo, y dentro de cada flujo, un pipeline de chaining ejecuta los pasos especializados. En LangChain, RunnableBranch encapsula exactamente esto: cada rama es una cadena independiente.
Muchos sistemas llamados «agentes» en producción son realmente esta combinación: un router en la entrada y pipelines chaining en cada rama. El branding agéntico oculta una arquitectura bastante convencional.
¿Cuándo debo usar Routing en lugar de un solo pipeline?
Cuando el flujo de ejecución depende de las características del input. Si un usuario puede pedir información, hacer una reserva, o reportar un error, Routing clasifica la intención y dirige cada caso a su handler especializado. Un pipeline único intentaría cubrir todos los casos y terminaría siendo mediocre en cada uno.
¿Qué tipo de routing es más rápido?
Rule-based routing es el más rápido y determinista. Funciona con if-else, regex o match de keywords. El trade-off es que no generaliza a inputs no previstos. Para categorías bien definidas y alto volumen, es la opción correcta. Embedding-based queda en segundo lugar, la operación de similitud coseno es prácticamente instantánea.
¿Puedo combinar varios tipos de routing?
Sí. Un patrón común y efectivo es usar rule-based como primer filtro para casos obvios y LLM-based como fallback para inputs que no encajan en las reglas. Esto reduce costos y latencia sin perder cobertura. Esencialmente, pagas con tokens solo lo que las reglas no resuelven.
¿Es necesario un fallback en Routing?
Sí. Los inputs no clasificados rompen el sistema. Siempre define una ruta por defecto que maneje casos ambiguos, ya sea pidiendo clarificación al usuario o derivando a un handler genérico. Un router sin fallback es una bomba de tiempo.
¿Qué es Auto-Flow en Google ADK?
Es el mecanismo de Google ADK para delegación automática basada en LLM. El agente principal evalúa la solicitud y decide cuál sub-agente especializado debe manejarla. No necesitas escribir lógica de branching explícita, el modelo mismo gestiona la delegación. Es útil, pero pierde transparencia: no ves fácilmente por qué el agente eligió una ruta sobre otra.
¿Cuándo Routing introduce más problemas que beneficios?
Cuando el flujo es predecible y lineal. Si siempre ejecutas los mismos pasos en el mismo orden, Routing añade latencia y complejidad innecesaria. Un Prompt Chaining simple es más barato, más rápido y más fácil de debuggear.
Conclusión
Routing no hace más inteligente al modelo. Hace más direccional al sistema. La diferencia importa: un pipeline mal dirigido produce output correcto en el camino equivocado.
En la práctica, la mayoría de implementaciones útiles de Routing combinan rule-based como filtro rápido con LLM-based como red de seguridad. El router perfecto no existe, pero uno bien diseñado reduce el ruido entre la intención del usuario y la acción del sistema.