
El problema que resuelve la paralelización
Un pipeline secuencial es predecible: paso A, luego B, luego C. El problema es que el tiempo total es la suma de todos los pasos. Si cada llamada al modelo tarda 2 segundos y tienes 5 pasos, el usuario espera 10 segundos.
La realidad es que muchos de esos pasos no dependen entre sí. Analizar el sentimiento de un texto, extraer entidades nombradas, y generar un resumen, las tres operaciones pueden ejecutarse al mismo tiempo. El resultado de una no necesita el resultado de la otra. Ejecutarlas secuencialmente es un desperdicio de tiempo.
La paralelización es la respuesta. Identifica las partes del flujo que son independientes y las ejecuta concurrentemente. El tiempo total tiende al máximo de las ramas, más el overhead de coordinación y el coste del fan-in. En el ejemplo anterior, las tres llamadas que antes sumaban 6 segundos se ejecutan solapadas, el resultado real depende de la rama más lenta y de cuanto cueste reunir los outputs.
Chaining maneja la secuencia, Routing decide el camino, Parallelization comprime el tiempo. Los tres juntos forman la columna vertebral de un sistema agéntico funcional, y en producción es frecuente verlos encadenados: un router dispara ramas paralelas que a su vez contienen pipelines secuenciales.
Arquitectura básica
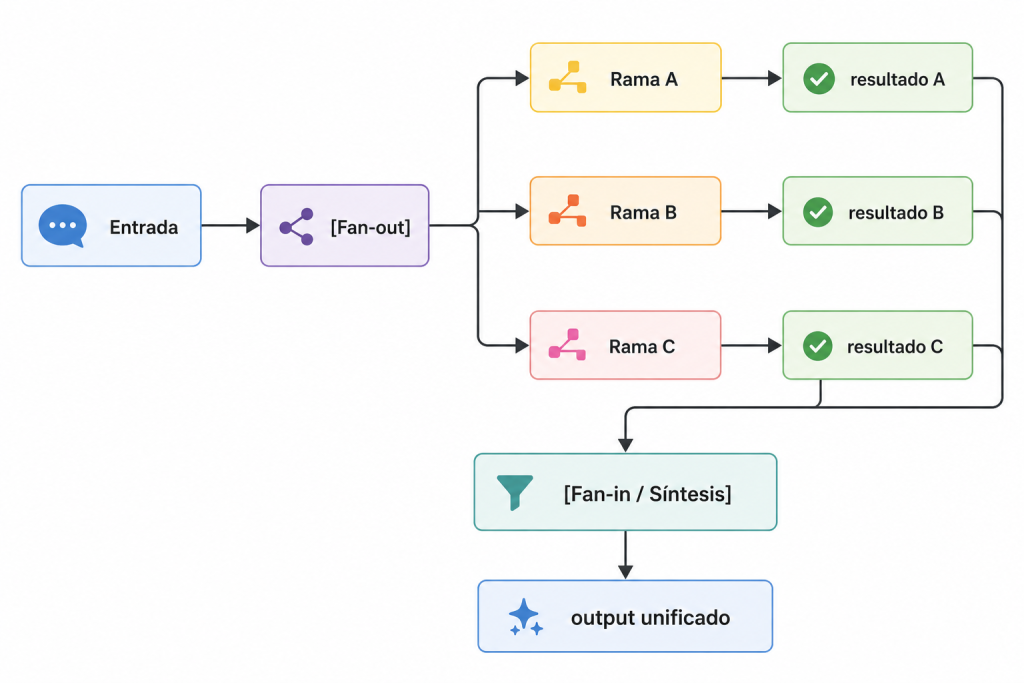
El patrón tiene dos fases: divergencia y convergencia.
- Fan-out: La fase de divergencia. El trabajo se divide en ramas independientes que se ejecutan simultáneamente.
- Ramas paralelas: Las tareas concurrentes. Cada una opera sin conocer el resultado de las otras.
- Fan-in: La fase de convergencia. Los resultados se recogen y combinan en un output coherente.
La topología es esencialmente un abanico: una entrada se expande en múltiples ramas y luego se contrae en una salida. El punto de convergencia es crítico, es donde los resultados paralelos se integran y donde la mayoría de los errores de diseño se hacen visibles.
La decisión clave aquí es identificar las dependencias reales. Si la rama B necesita el resultado de la rama A, no son paralelas, son secuenciales disfrazadas. En producción, esto falla cuando las dependencias son ocultas: dos ramas que leen el mismo recurso compartido, o una rama que asume datos que otra esta modificando. El error tipico es paralelizar algo que parece independiente hasta que la carga lo demuestra.
Ejemplo: estructura de un pipeline paralelo
Un pipeline paralelo funcional en Python se reduce a esto:
import asyncio
async def analyze_sentiment(text: str) -> dict:
# Simula llamada a LLM
return await llm_call("Analiza el sentimiento: " + text)
async def extract_entities(text: str) -> dict:
return await llm_call("Extrae entidades nombradas: " + text)
async def generate_summary(text: str) -> dict:
return await llm_call("Resume en tres líneas: " + text)
async def process_document(text: str) -> dict:
# Fan-out: ejecuta las tres tareas concurrentemente
sentiment, entities, summary = await asyncio.gather(
analyze_sentiment(text),
extract_entities(text),
generate_summary(text)
)
# Fan-in: combina resultados
return {
"sentiment": sentiment,
"entities": entities,
"summary": summary,
}Tres llamadas al modelo que antes sumaban 6 segundos en secuencia ahora se ejecutan solapadas. El paso de combinación es determinista, normalmente no requiere otra llamada al modelo. Es la forma más eficiente de paralelización porque el fan-in se reduce a un merge de diccionarios.
Los tres tipos de paralelismo
En la literatura sobre sistemas LLM, suelen distinguirse tres formas de paralelismo. Cada una tiene un perfil de complejidad y uso distinto.
Task parallelism
Cada rama ejecuta una tarea diferente con el mismo input. Es el patrón mas simple: analizar, extraer, resumir, operaciones distintas sobre el mismo texto.
El beneficio es directo: el tiempo total se aproxima al de la rama mas lenta. No hay coordinación entre ramas, lo que simplifica el diseño. El límite es que solo funciona cuando las tareas son genuinamente independientes, y en producción, «genuinamente» es la palabra que mas se rompe. Dos ramas que parecen independientes pueden compartir un rate limit, una conexion a base de datos, o un archivo de logs.
En LangChain se implementa con RunnableParallel:
from langchain_core.runnables import RunnableParallel
map_chain = RunnableParallel({
"sentiment": analyze_chain,
"entities": extract_chain,
"summary": summarize_chain,
})
results = map_chain.invoke({"text": "El documento a analizar..."})
# results = {"sentiment": "...", "entities": "...", "summary": "..."}RunnableParallel dispara todas las cadenas simultáneamente. El resultado es un diccionario con las claves que definiste. Simple, predecible, efectivo.
Fan-out / Fan-in
El mismo tipo de tarea se ejecuta sobre diferentes inputs. Por ejemplo, resumir 10 documentos diferentes, o traducir un texto a 5 idiomas. Cada rama hace lo mismo, pero con datos distintos.
Aquí es donde Parallelization brilla. Un pipeline secuencial sobre 10 documentos tarda 10 veces mas. Con fan-out/fan-in, tarda lo que tarda un solo documento, mas el costo de la convergencia.
El punto de convergencia es mas complejo que en task parallelism. No basta con juntar resultados en un diccionario, necesitas sintetizarlos. Un agente merger o un prompt de síntesis es el siguiente paso natural.
# Fan-out: mismos prompt, diferentes inputs
documents = ["doc1...", "doc2...", "doc3...", "doc4..."]
summaries = await asyncio.gather(*[
summarize(doc) for doc in documents
])
# Fan-in: síntesis de todos los resúmenes
final = await synthesize(summaries)Map-reduce
La version escalada de fan-out/fan-in. Se divide un conjunto grande de datos en chunks, se procesa cada chunk en paralelo, y se reduce el resultado en una o varias pasadas.
Es el patrón más potente y complejo. Requiere que la operación de reducir sea asociativa, es decir, que reducir (A, B) y luego con C produzca el mismo resultado que reducir (B, C) y luego con A. No todas las operaciones de síntesis cumplen esto.
En la practica, map-reduce con LLMs aparece en escenarios concretos: Resumir un libro de 500 paginas (dividir en capítulos, resumir cada uno, sintetizar los resúmenes), o analizar un corpus de documentos legales. El error típico es aplicarlo a conjuntos pequeños — si puedes procesar los datos en una sola pasada, map-reduce añade complejidad sin retorno.
Comparativa
| Tipo | Latencia | Coste | Precisión | Complejidad | Mantenimiento |
|---|---|---|---|---|---|
| Task parallelism | Baja (max de ramas) | Medio (una llamada por rama) | Alta | Baja | Bajo |
| Fan-out / Fan-in | Baja (max de ramas) | Alto (N llamadas + síntesis) | Media-Alta | Media | Medio |
| Map-reduce | Media (multi-pasada) | Muy alto (N + M llamadas) | Media | Alta | Alto |
Parallelization en la práctica: dónde colocarlo
La posición del paralelismo en el flujo determina su impacto. Hay tres ubicaciones comunes:
- Paralelización en la entrada: Procesa el input del usuario desde múltiples ángulos simultáneamente. Un chatbot que analiza sentimiento, extrae intención, y detecta entidades en paralelo antes de decidir como responder. Es el uso mas directo y el que ofrece mayor ahorro de latencia.
- Paralelización intermedia: Aparece después de un paso de preprocessing. Un sistema de análisis financiero primero extrae datos relevantes, luego ejecuta en paralelo: Detección de anomalías, calculo de métricas, y generación de alertas. Aquí es donde Parallelization gana sobre Chaining puro: las tres operaciones usan los mismos datos de entrada y no dependen entre si.
- Paralelización de generación: Produce múltiples candidatos simultáneamente para luego seleccionar el mejor. Esencialmente es A/B testing automatizado: Generar tres respuestas y dejar que un evaluador elija la mas adecuada. Funciona bien cuando la calidad del output es prioritaria sobre la velocidad.
La tentación es poner paralelismo en todas partes. No lo hagas. Cada capa de fan-out/fan-in añade una superficie de fallo; una rama que timeout, un merge que falla silenciosamente, un resultado que llega desordenado. En producción, el overhead de gestionar tres niveles de paralelismo supera el beneficio de la velocidad en más ocasiones de las que cabría esperar.
Como medir si tu paralelismo funciona
Un pipeline paralelo sin metricas es una apuesta. No sabes si estas ahorrando tiempo o simplemente gastando mas tokens. Estos son los indicadores minimos:
- Ratio de aceleracion — tiempo secuencial dividido por tiempo paralelo. Un ratio de 3x con 3 ramas significa que el paralelismo es eficiente. Un ratio de 1.2x indica que el overhead de coordinacion consume el beneficio.
- Tiempo de convergencia — cuanto tarda el paso de fan-in. Si la convergencia tarda mas que las ramas paralelas, el paralelismo es contraproducente.
- Coste por decision — en un pipeline paralelo, cada rama es una llamada adicional al modelo. Si el coste total supera el presupuesto, reducir el numero de ramas es mas efectivo que optimizar los prompts individuales.
- Tasa de timeout — una rama lenta bloquea la convergencia. Monitorear timeouts por rama identifica cuellos de botella. Si una rama supera consistentemente el tiempo de las otras, merece ejecucion separada o un modelo mas rapido.
No necesitas un dashboard completo. Un log con {rama, tiempo, tokens, status} y un resumen de ratio de aceleracion diario es suficiente para mantener el pipeline bajo control. Lo que importa es detectar cuando el paralelismo deja de ser eficiente.
Anti-patrones que rompen el paralelismo
Los errores aquí no son técnicos, son de diseño. El codigo de paralelismo rara vez falla; falla la decisión de que paralelizar y cuando.
- Falso paralelismo: Ejecutar concurrentemente tareas que tienen dependencias ocultas. La rama B usa datos que la rama A esta modificando. Funciona la mayor parte del tiempo, pero produce resultados inconsistentes en condiciones de carga. Es el error mas peligroso porque es difícil de reproducir.
- Convergencia costosa: Paralelizar 10 tareas cuyo merge requiere 5 llamadas adicionales al modelo. El tiempo total aumenta en lugar de reducirse. La regla práctica: si el fan-in cuesta más que las ramas, no paralelizar.
- Sin manejo de timeout: Una rama lenta bloquea todo el pipeline. Sin timeouts, un solo fallo de red o un modelo en cola detiene la convergencia. Cada rama necesita un timeout independiente y un fallback.
- Over-parallelization: Disparar 20 ramas concurrentes cuando el proveedor tiene un límite de 10 requests por segundo. Las ramas excedentes se ejecutan secuencialmente de todas formas, pero con el overhead adicional de gestión.
- Paralelizando tareas triviales: El overhead de crear tareas concurrentes supera el ahorro para operaciones ligeras. Si una tarea tarda menos de 100ms, el costo de asyncio o multiprocessing la hace mas lenta que la versión secuencial.
Cuándo NO usar Parallelization
Parallelization es solución a un problema específico: Tareas independientes que consumen tiempo de I/O. Si tus pasos son secuenciales por naturaleza, la paralelización añade complejidad sin retorno.
Ejemplos concretos donde la paralelización sobra:
- Un pipeline donde cada paso necesita el resultado del anterior es Chaining puro.
- Un sistema que genera una sola respuesta, no hay que paralelizar una tarea.
- Operaciones CPU-bound ligeras, el overhead de concurrencia supera el beneficio en Python.
La regla práctica; si puedes describir el flujo como «haz A, espera el resultado, luego haz B con ese resultado», no necesitas paralelización. Útilizala cuando la pregunta real es «¿Puedo hacer A, B y C al mismo tiempo?».
Parallelization y los demas patrones
La combinación más común en producción es Routing → Parallelization → Prompt Chaining. El router decide el flujo, dentro de cada flujo se ejecutan tareas concurrentes, y los resultados alimentan un pipeline de chaining para procesamiento final. En LangChain, RunnableBranch puede contener RunnableParallel en cada rama, que a su vez contiene cadenas secuenciales.
Function calling puede verse como una forma de subroutine routing donde el modelo selecciona una herramienta específica. Y esas herramientas pueden ejecutarse en paralelo; consultar base de datos, verificar API externa, y leer archivos locales simultáneamente. Cuando un agente «piensa» antes de actuar, a menudo esta ejecutando varias verificaciones en paralelo antes de decidir.
¿Cuándo debo usar Parallelization en lugar de Prompt Chaining?
La prueba es simple, pregunta «¿Puedo ejecutar B sin conocer el resultado de A?». Si la respuesta es si, Parallelization reduce el tiempo total. Si B necesita el resultado de A, Chaining es la opción correcta, paralelizar tareas dependientes produce resultados inconsistentes.
¿Parallelization funciona con modelos locales?
Si, pero el beneficio depende del hardware. Con un solo GPU, las llamadas concurrentes a un modelo local se ejecutan secuencialmente en cola, el modelo suele procesar una solicitud a la vez. El verdadero paralelismo local requiere multiples GPUs o instancias separadas del modelo. En cambio, si las ramas paralelas usan diferentes tipos de operacion (una llama al modelo, otra consulta una base de datos, otra hace calculos), el beneficio existe incluso con un solo GPU porque las operaciones no compiten por el mismo recurso.
¿Cual es el riesgo principal de Parallelization?
El falso paralelismo, ejecutar concurrentemente tareas que en realidad tienen dependencias ocultas. Produce resultados inconsistentes y es dificil de detectar porque funciona la mayor parte del tiempo. El segundo riesgo es la convergencia costosa, paralelizar 10 tareas cuyo merge requiere 5 llamadas adicionales al modelo. En ambos casos, el tiempo total aumenta en lugar de reducirse.
¿Cuantas ramas paralelas es demasiado?
Depende del límite de rate de tu proveedor y del costo de la convergencia. A medida que aumenta el numero de ramas, el coste de coordinación y síntesis tiende a crecer. A partir de cierto punto suele ser más adecuado un enfoque map-reduce que un fan-out/fan-in simple. La regla práctica: Empieza con 3 ramas y mide el ratio de aceleración antes de añadir mas.
¿Que es fan-out/fan-in?
Es la topologia basica de paralelización: fan-out divide el trabajo en ramas independientes que ejecutan concurrentemente, fan-in las reúne en un punto de convergencia para síntesis o merge. Esencialmente es un abanico, una entrada se expande en múltiples ramas y luego se contrae en una salida.
¿Parallelization y Routing son compatibles?
Si. De hecho, es comun usar Routing para decidir que conjunto de tareas paralelas activar, y dentro de cada rama, ejecutar sub-tareas concurrentemente. La combinación Routing → Parallelization → Chaining es un patrón frecuente en producción. Cada patrón resuelve un problema distinto y juntos cubren la mayoría de los flujos agénticos.
Conclusión
La paralelización no hace mas inteligente al modelo. Hace mas eficiente al sistema. La diferencia importa, un pipeline que tarda 10 segundos cuando podía tardar 2 pierde usuarios antes de producir resultados.
En la práctica, la mayoria de implementaciones utiles de paralelización empiezan con task parallelism simple, tres tareas independientes, un diccionario de resultados, un paso de combinación determinista. La versión elegante es la que no necesita llamada adicional al modelo para el fan-in. El paralelismo perfecto no existe, pero uno bien diseñado reduce la latencia total sin sacrificar calidad.