
El problema que Reflection resuelve
Un modelo de lenguaje produce su mejor output en el primer intento. La mayoria de las veces es suficiente. Pero hay tareas donde el primer intento falla de forma predecible: Código con edge cases olvidados, análisis que omite perspectivas clave, contenido que no cumple restricciones específicas.
Un humano escribe, lee, corrige. Un LLM escribe y se queda en silencio. Reflection cierra esa brecha introduciendo un bucle de feedback: Genera output, evalúa contra criterios, mejora.
Lo que esto no hace es convertir un modelo incapaz en uno competente. Si el modelo no puede generar código correcto la primera vez, probablemente tampoco pueda corregirlo la segunda. Reflection estabiliza la calidad de un modelo que ya funciona, no lo repara.
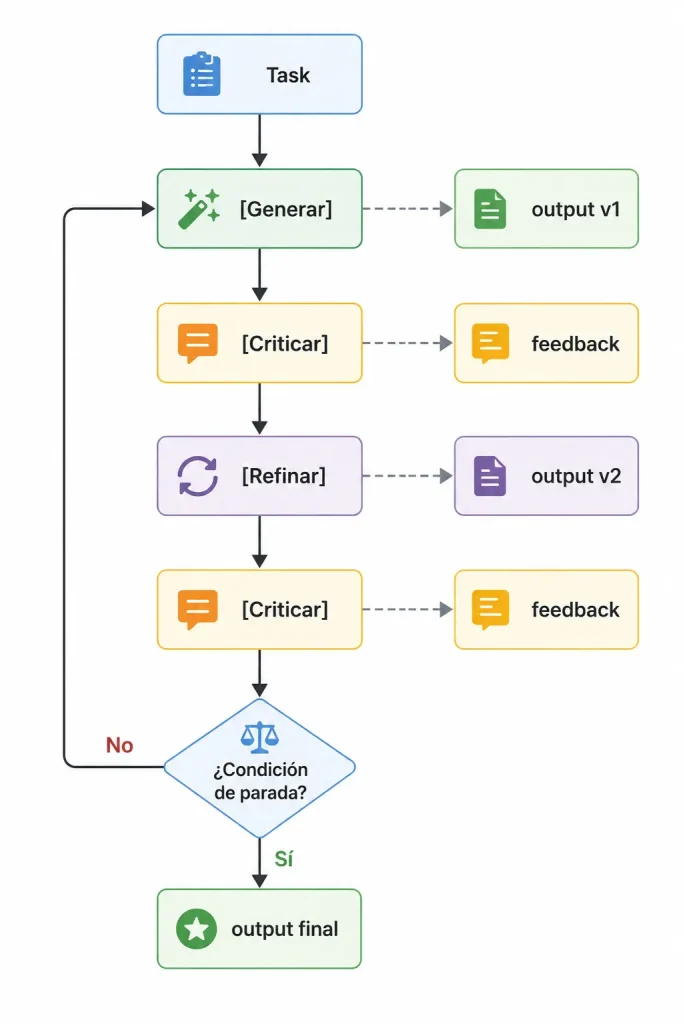
Arquitectura básica
El patrón tiene cuatro fases:
- Generación: El agente produce el output inicial.
- Crítica: Una evaluación independiente analiza el output contra criterios específicos.
- Refinamiento: El agente genera una versión mejorada basándose en la crítica.
- Iteracion: El ciclo se repite hasta cumplir una condición de parada.
Usar dos agentes distintos: Un Generator enfocado en producción y un Critic con instrucciones de «ingeniero senior» o «revisor exhaustivo» previene el sesgo de confirmación. Un modelo que acaba de generar codigo tiende a excusar sus propios errores. Un agente separado no tiene esa inercia.
Ejemplo: Bucle de reflection funcional
import asyncio
import json
from dataclasses import dataclass
@dataclass
class ReflectionResult:
output: str
iterations: int
accepted: bool
total_tokens: int
async def reflect(
task: str,
criteria: dict,
max_iter: int = 3,
generate_fn=None,
critique_fn=None,
) -> ReflectionResult:
"""Bucle de reflection con control de contexto y parada temprana."""
output = await generate_fn(task, [])
context = [task]
total_tokens = 0
for i in range(max_iter):
feedback = await critique_fn(task, output, criteria)
total_tokens += len(feedback) # proxy de tokens
if "OUTPUT_ACCEPTABLE" in feedback:
return ReflectionResult(output, i + 1, True, total_tokens)
# Truncar contexto: mantener solo las 2 criticas mas recientes
context = [task] + context[-2:]
context.append(f"Critique {i+1}: {feedback}")
output = await generate_fn("Refine based on critiques.", context)
return ReflectionResult(output, max_iter, False, total_tokens)Tres iteraciones máximo. Condición de parada explícita. Contexto truncado a las dos críticas más recientes para evitar que el historial inunde la ventana del modelo. Es la estructura que he usado en sistemas reales porque equilibra calidad y coste de forma predecible.
Lo que aprendimos a mal
La primera vez que implementamos Reflection, lo hicimos con 5 iteraciones y el mismo modelo para Generator y Critic. Parecía buena idea: Un solo modelo, menos infraestructura, y «si 3 iteraciones ayudan, 5 ayudaran el doble».
Fue un desastre. El modelo entraba en bucles donde el Critic señalaba un problema, el Generator lo «arreglaba» introduciendo otro, y el Critic señalaba el nuevo problema. En la iteración 4, el output era peor que el original. Y como usábamos el mismo modelo, el Critic tendia a aceptar sus propias correcciones anteriores en lugar de evaluar el resultado final.
Lo que hicimos: Bajamos a 3 iteraciones, separamos Generator y Critic, y añadimos la condición de parada temprana. El resultado fue mejor y más barato. La lección: Más iteraciones no es más calidad. Es mas ruido.
Y eso no fue el peor problema. Lo que realmente nos costó tiempo fue el overflow de contexto. Cada iteración añadía el output anterior más la crítica al historial, y en tareas con outputs largos (generación de código de 200 lineas), la ventana de contexto se llenaba en la segunda iteración. El modelo empezaba a alucinar porque perdía el contexto original de la tarea. Lo que hicimos; truncar el historial a las dos críticas más recientes y mantener solo la tarea original. Funcionó, pero fue una corrección que deberíamos haber hecho desde el principio.
Los dos enfoques de Reflection
En la literatura sobre sistemas LLM, se distinguen dos formas de implementar la reflexion. Cada una tiene un perfil de objetividad y costo distinto.
Auto-reflexión
El mismo modelo genera y revisa su output. Una sola llamada, un prompt que incluye tanto la tarea como la instrucción de auto-revisión.
Funciona para errores obvios (sintaxis, formato, ortografía), pero se rompe cuando el fallo es conceptual. Pedirle a un modelo que encuentre sus propios errores de lógica es como pedirle a alguien que revise su propio trabajo después de tres horas seguidas, pasa por alto lo que acaba de escribir.
En LangChain se implementa con una cadena secuencial, generación seguida de auto-evaluación. Es barato y rapido, pero la calidad de la revisión tiene un techo bajo.
Critic separado
Un agente distinto, con instrucciones diferentes, evalua el output. El Generator se enfoca en producción. El Critic se enfoca en hallar fallos.
Esta separación es lo que hace efectivo al patrón. El Critic no invirtió tokens en el output original. Puede ser mas severo porque no tiene apego al resultado. En nuestros tests, la diferencia en calidad de revisión entre un Critic separado y la auto-reflexion era clara, el Critic independiente detectaba errores conceptuales que la auto-reflexión pasaba por alto consistentemente.
Pero tiene un precio, duplica las llamadas al modelo. Si el Generator ya usa un modelo grande, el Critic añade latencia y coste. Si no compensa el overhead, la auto-reflexión suele ser suficiente.
Comparativa
| Enfoque | Coste | Objetividad | Complejidad | Mejora típica |
|---|---|---|---|---|
| Auto-reflexión | Bajo (1 modelo) | Baja (sesgo de confirmación) | Baja | Errores superficiales |
| Critic separado | Medio (2 modelos) | Alta | Media | Errores conceptuales y superficiales |
Reflection en la práctica: dónde colocarlo
La posición del bucle de reflection en el flujo determina su impacto. Hay tres ubicaciones comunes:
- Reflection en la salida: El punto mas natural. El pipeline genera un output y un critic lo revisa antes de entregarlo al usuario. Es el uso más directo, código generado, contenido escrito, análisis completado. Aquí es donde Reflection ofrece el retorno mas claro porque la revisión ocurre justo antes de la entrega.
- Reflection intermedia: aparece dentro de un pipeline más largo. Un sistema de análisis genera datos intermedios, los revisa, y los usa como input para el siguiente paso. Es menos común pero más efectivo cuando los errores tempranos se amplifican en pasos posteriores. Corregir en el paso 2 es mas barato que corregir en el paso 5.
- Reflection como puerta de calidad: un critic actua como gatekeeper antes de que el output avance. Si no pasa la revisión, se rechaza y se regenera. Esencialmente es un filtro de calidad con bucle de reintento. Funciona bien en sistemas donde la consistencia es prioritaria sobre la velocidad.
Ejemplo de código: Reflection con LangChain
El ejemplo anterior era un bucle mínimo. En produccion, necesitas manejo de errores, parsing robusto, y control de retries. Así es como se ve una implementacion funcional:
import asyncio
import json
from typing import Optional
from langchain_core.language_models import BaseChatModel
from langchain_core.messages import HumanMessage, SystemMessage
CRITIC_PROMPT = """You are a senior reviewer. Evaluate this output against the criteria.
If it passes all criteria, respond with exactly: OUTPUT_ACCEPTABLE
Otherwise, list specific issues with line references.
Task: {task}
Output: {output}
Criteria: {criteria}
"""
GENERATOR_PROMPT = """Generate the requested output.
Task: {task}
"""
async def production_reflect(
task: str,
criteria: dict,
generator: BaseChatModel,
critic: BaseChatModel,
max_iter: int = 3,
temperature: float = 0.3,
) -> dict:
"""Reflection con control de errores y parsing estructurado."""
history = [SystemMessage(content=GENERATOR_PROMPT.format(task=task))]
output = ""
iterations_used = 0
accepted = False
for i in range(max_iter):
try:
# Generar
resp = await generator.ainvoke(history, temperature=temperature)
output = resp.content.strip()
iterations_used = i + 1
# Criticar
critic_msg = HumanMessage(
content=CRITIC_PROMPT.format(
task=task, output=output, criteria=json.dumps(criteria)
)
)
critique_resp = await critic.ainvoke([critic_msg], temperature=0.1)
feedback = critique_resp.content.strip()
if "OUTPUT_ACCEPTABLE" in feedback:
accepted = True
break
# Refinar: añadir critica al historial y regenerar
history.append(HumanMessage(content=f"Review feedback: {feedback}"))
history.append(HumanMessage(content="Refine the output addressing all issues."))
except Exception as e:
# Si falla, devolver el output actual con bandera de error
return {
"output": output,
"iterations": iterations_used,
"accepted": False,
"error": str(e),
}
return {
"output": output,
"iterations": iterations_used,
"accepted": accepted,
}Nota las decisiones de diseño: temperatura baja en el Critic (0.1) para consistencia, parsing por string literal en lugar de JSON para evitar que el modelo rompa el formato, y un try/externo que captura fallos de red o timeouts sin colgar el pipeline. Sin estas protecciones, un timeout del Critic bloquea toda la petición.
El parsing por string literal es una decisión fea pero funcional. Probamos con JSON estructurado primero, el Critic respondía con objetos JSON, y el modelo rompía el formato en el 10% de los casos. Un try-except alrededor del json.loads() ayudaba, pero añadir una capa de parsing que fallaba regularmente era más ruido que señal. El string literal es más sucio, pero funciona.
Como medir si tu reflection funciona
Un bucle de reflection sin metricas es un gasto justificado por fe. Estos son los indicadores mínimos:
- Tasa de aceptación por iteración: En que iteración el critic declara el output aceptable. Si el 60% pasa en la primera iteración, el bucle es innecesario para esos casos. Si el 80% llega a la ultima iteración, las instrucciones del critic son demasiado estrictas o el generator necesita mejora.
- Mejora marginal por iteración: Cuanto mejora el output entre iteraciones. Si la iteracion 3 aporta menos del 5% de mejora sobre la 2, el costo adicional no se justifica. El retorno decreciente es real y medible.
- Coste por output aceptable: Tokens totales divididos por outputs que pasaron la revisión. Si el costo se triplica con una mejora del 10%, la relación es negativa.
- Crecimiento del contexto: tokens acumulados en el historial de conversación. Cada iteración añade output + crítica. Sin control, el contexto crece linealmente y alcanza el límite del modelo. Truncamos el historial después de la tercera iteracion, mantenía la calidad sin inflar el contexto.
No necesitas un dashboard completo. Un log con {iteracion, tokens, feedback_length, accepted} y un resumen semanal es suficiente para mantener el bucle bajo control.
Anti-patrones que rompen reflection
Los errores aquí no son técnicos. Son de diseño. El código de reflection rara vez falla. Falla la decisión de que revisar y cuantas veces.
- Bucles sin límite: Sin máximo de iteraciones o condición de parada, el agente se ejecuta hasta agotar el contexto o el rate limit. En producción, esto se traduce en facturas inesperadas y timeouts en cascada.
- Criterios vagos: Pedir al critic que «verifique la calidad» sin dimensiones específicas produce feedback inútil. «El codigo es bueno» no ayuda. «Falta manejo de ValueError para n < 0» si ayuda.
- Reflection en tareas simples: Si un solo prompt produce resultados aceptables, añadir un bucle de revisión desperdicia recursos. La reflection vale la pena cuando el costo del error supera el costo de la revisión.
- Ignorar el crecimiento del contexto: Cada ciclo añade el output anterior más la critica al historial. Conversaciones largas agotan la ventana de contexto rapidamente. El error típico es acumular historial sin truncar.
- Critic demasiado permisivo: Un critic que acepta todo convierte la reflection en un pasarela cosmética. El Critic debe tener criterios mas estrictos que el Generator. Si el Critic acepta lo que el Generator considera bueno, no hay revisión real.
El anti-patron mas peligroso es el Critic que empeora el output. Hemos visto casos donde el Critic senalaba «errores» que no eran errores, estilo de codificación preferido, estructura alternativa, y el Generator los «corregía» introduciendo bugs reales. Lo que funcionó: El Critic evaluando contra criterios objetivos (funcionalidad, seguridad, rendimiento), no contra preferencias subjetivas.
Cuándo NO usar Reflection
Reflection es una solución a un problema específico, output de primer intento insuficiente para el caso de uso. Si un solo prompt produce resultados aceptables, Reflection añade costo sin retorno.
Ejemplos concretos donde Reflection sobra:
- Clasificación de texto en categorías predefinidas: Un solo paso es suficiente.
- Extracción de datos estructurados con schema claro: El modelo cumple o no cumple, no hay espacio para iteración útil.
- Generación de contenido simple (títulos, descripciones cortas): La revisión no aporta valor medible.
Si el costo del error es bajo y la tarea es predecible, un solo prompt es más eficiente. Usa Reflection cuando la calidad del output es prioritaria y el primer intento falla de forma predecible.
Reflection y los demas patrones
La combinación más común en producción es Chaining → Reflection. Un pipeline genera output paso a paso, y un critic revisa el resultado final. En LangChain, una cadena secuencial puede terminar con un nodo de reflection opcional.
Reflection tambien se combina con Routing. Un router clasifica la tarea y decide si merece revisión. Tareas críticas (código de producción, análisis financiero) pasan por reflection. Tareas rutinarias (resumir, clasificar) no. La decisión de aplicar reflection es una forma de routing.
Con Parallelization, la combinacion es Parallelization → Reflection. Múltiples ramas generan candidatos simultaneamente, y un critic selecciona el mejor. Esencialmente es A/B testing automatizado con revisión inteligente.
¿Cuándo debo usar Reflection en lugar de un solo prompt?
Cuando la calidad del output importa mas que la velocidad. Generacion de codigo, contenido largo, analisis complejo. La prueba es simple: ejecuta el prompt una vez y mide la tasa de errores. Si supera el 15%, Reflection vale la pena. Si esta por debajo, un solo prompt es mas eficiente.
¿Es mejor un Critic separado o auto-reflexión?
Un Critic separado es más objetivo. La auto-reflexión sufre de sesgo de confirmación, el modelo tiende a validar su propio trabajo en lugar de encontrar fallos reales. El costo es una llamada adicional al modelo, pero la calidad de la crítica mejora significativamente. En producción, la diferencia es medible.
¿Cuántas iteraciones de Reflection?
Depende del caso, pero la mayoría de sistemas en producción se benefician de 2-3 iteraciones máximo. Despues de eso, la mejora marginal disminuye rapidamente y el costo crece linealmente. Siempre define una condición de parada explícita. Un bucle sin límite es una bomba de tiempo financiera.
¿Qué es una condición de parada en Reflection?
Es el criterio que termina el bucle de reflection. Puede ser un máximo de iteraciones (ej: 3 intentos), una señal explicita del critic (ej: «OUTPUT_ACCEPTABLE»), o un umbral de confianza. Sin condición de parada, el bucle se ejecuta hasta agotar el contexto o el rate limit.
¿Reflection funciona con modelos locales pequeños?
Sí, pero el beneficio depende de la capacidad del modelo. Un modelo de 7B puede mejorar código simple con Reflection, pero para tareas complejas necesitas al menos 13B. La reflexión amplifica las capacidades del modelo, no las crea. Un modelo incapaz de generar código correcto en el primer intento probablemente tampoco será capaz de corregirlo en el segundo.
¿Cómo evito que el bucle de Reflection crezca indefinidamente en contexto?
Limita el historial de conversación a las iteraciones relevantes. En lugar de acumular todo el historial, pasa solo el output actual y la crítica más reciente. O usa resúmenes compresivos de iteraciones anteriores. Lo que vimos fue que truncar después de la tercera iteración mantenía la calidad sin inflar el contexto.
Conclusión
Reflection funciona. Pero no es bonito. Cuesta más de lo que parece, requiere métricas que nadie quiere mantener, y siempre hay ese caso donde el Critic se vuelve demasiado permisivo o demasiado severo y tienes que reescribir sus criterios.
Lo que hace en la práctica es reducir la variabilidad del output. Un modelo competente produce buenos resultados la mayoría de las veces. Reflection hace que esos buenos resultados sean consistentes, incluso en los días en que el modelo tiene un mal día.
La implementación que funciona no es la mas elegante. Es la que tiene un Critic con criterios claros, un máximo de iteraciones razonable, y un plan B cuando el bucle falla. Todo lo demás es optimizacion.