
Cuando un solo paso no alcanza
Hay tareas que no caben en un prompt. Investigar un tema técnico, generar un informe de análisis competitivo, o diseñar una arquitectura de sistemas; muchas de estas tareas no se resuelven bien con una sola llamada al modelo. Intentarlo produce outputs superficiales, porque el modelo toca cada tema por encima, pero no profundiza en ninguno.
Planning aborda esto de forma directa. En lugar de pedirle al modelo que haga todo de una vez, le pide que primero diseñe un plan y luego lo ejecute paso a paso. Cada paso del plan se convierte en una sub-tarea con entrada definida, criterio de salida, y dependencia explícita respecto a los pasos anteriores.
Nota: Planning no es un patrón canónico único en la literatura de LLMs, sino un paraguas conceptual sobre varias técnicas relacionadas: Plan-and-execute, task decomposition, graph-based orchestration, y multi-step tool use. Lo que sigue es una síntesis práctica de esas técnicas bajo un mismo marco.
Pero Planning no es solo «dividir la tarea». La pregunta real es: ¿El camino se conoce de antemano o se descubre durante la ejecución? Si el camino es fijo, usas un workflow determinado. Si el camino depende de lo que el agente encuentre en el camino, necesitas Planning.
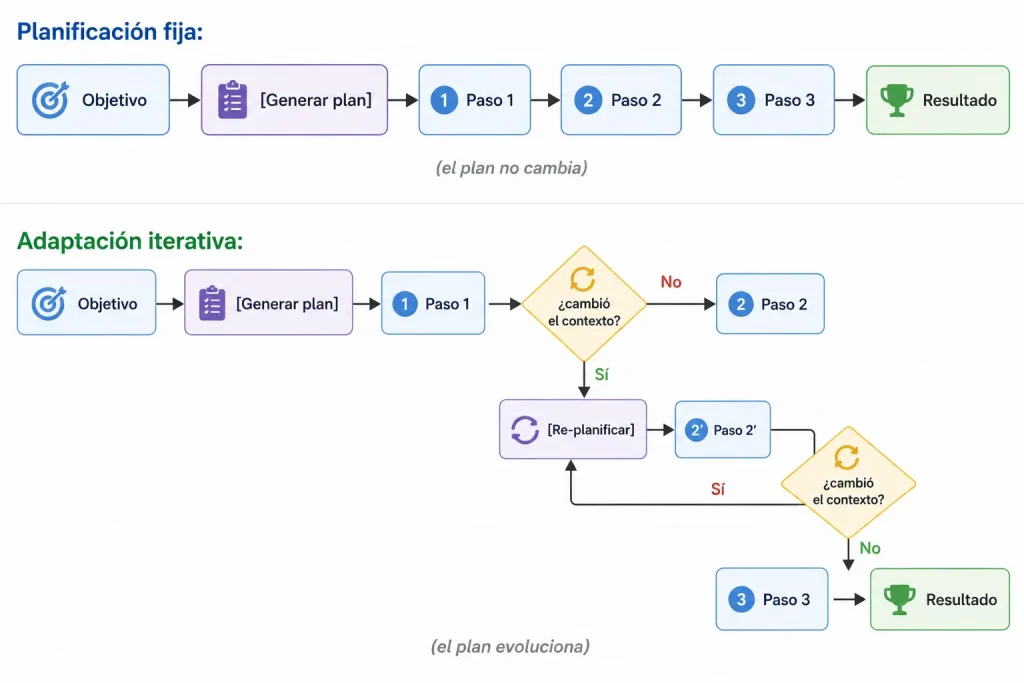
Planificación en la práctica: un espectro entre planificación fija y adaptación iterativa
En la práctica, Planning existe en un espectro entre dos extremos. La mayoría de sistemas reales son híbridos, pero entender los extremos ayuda a diseñar mejor.
Planificación fija: Algunos sistemas generan un plan inicial y lo ejecutan sin cambios, salvo fallos explícitos. Es predecible, facil de depurar, y funciona para procesos repetitivos. Si cada paso tiene una entrada y salida bien definidas, y no hay incertidumbre sobre que hacer cuando algo cambia, este enfoque es suficiente.
Adaptación iterativa: Otros sistemas introducen re-evaluación periódica o disparada por eventos para modificar el plan durante la ejecución. El agente evalua el resultado de cada paso, detecta si la información cambia el contexto, y reformula los siguientes pasos en consecuencia. Es mas flexible, pero menos predecible.
En el fondo, Planning no es un mecanismo de organización de tareas. Es un mecanismo para gestionar incertidumbre en la ejecución de tareas multi-step bajo información incompleta. La descomposición, la ejecución y la re-planificación no son fines en si mismas, sino herramientas para transformar un problema abierto en una secuencia de decisiones locales verificables.
Descomposición: El corazón del Planning
La capacidad de un agente para descomponer un objetivo en pasos ejecutables depende de dos factores: La calidad del prompt de planificación y la capacidad del modelo.
El prompt de planificación debe especificar:
- El objetivo final: Qué se considera «completado».
- Los criterios de descomposición: Cada paso debe ser autónomo, medible, y tener una salida concreta.
- Las dependencias: Qué pasos requieren el output de otros.
- Los límites: Máximo de pasos, restricciones de tiempo o recursos.
Pedirle al modelo «planifica esto» sin estructura tiende a producir planes genericos: «1. investigar, 2. analizar, 3. escribir». En la mayoria de casos, ese output no es ejecutable porque falta granularidad. Lo que funciona es especificar el formato del plan y los criterios que cada paso debe cumplir.
Y hay una distinción que conviene dejar clara antes de ver código: Planning es un patrón de arquitectura. CrewAI, LangGraph o Google ADK son implementaciones del patrón, no el patrón en si. Confundir herramienta con patrón lleva a soluciones acopladas a un framework en lugar de diseños que sobreviven a los cambios de tecnología.
En ese sentido, Planning es una familia de estrategias de control para ejecución multi-step en sistemas basados en LLMs. El modelo puede participar tanto en planificación como en ejecución y evaluación dentro de un loop orquestado. Separar esas responsabilidades es lo que permite que el patrón funcione en producción.
Ejemplo: Planner-Writer con CrewAI
from crewai import Agent, Task, Crew, Process
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
planner_writer = Agent(
role="Planificador y Ejecutor",
goal="Descomponer tareas complejas en pasos ejecutables y ejecutarlas.",
backstory=(
"Eres un analista técnico que siempre genera un plan estructurado "
"antes de actuar. Cada paso del plan tiene una entrada definida, "
"un criterio de éxito y una salida concreta."
),
llm=llm,
)
topic = "Análisis de patrones agénticos para sistemas LLM"
task = Task(
description=(
f"1. Crea un plan de análisis sobre: '{topic}'\n"
f" - Máximo 5 pasos.\n"
f" - Cada paso debe ser ejecutable de forma independiente.\n"
f" - Indica las dependencias entre pasos.\n"
f"2. Ejecuta cada paso del plan en orden.\n"
f"3. Genera un resumen final basado en los resultados."
),
expected_output=(
"Un informe con:\n"
"### Plan\n- Paso N: descripción (depende de: X)\n"
"### Ejecución\n- Resultado de cada paso.\n"
"### Conclusión\n- Síntesis de los hallazgos."
),
agent=planner_writer,
)
crew = Crew(agents=[planner_writer], tasks=[task], process=Process.sequential)
result = crew.kickoff()
print(result)El patrón Planner-Writer es la forma más simple de Planning. Un solo agente genera el plan y lo ejecuta. Funciona para tareas donde la especialización no varía entre pasos. Cuando cada paso requiere expertise distinta, escalas a multi-agente, pero eso es territorio del patrón Multi-Agent.
Re-planificación: Cuando el plan original ya no sirve
Aquí es donde Planning dinámico se diferencia del estático. La re-planificación ocurre cuando:
- Un paso produce un resultado inesperado que cambia el contexto.
- Falta información crítica para continuar.
- Un paso falla y necesita un enfoque alternativo.
- Se descubre que el plan original omite un aspecto importante.
El mecanismo es simple en teoría. El agente evalúa el resultado de cada paso, decide si el plan sigue siendo válido, y si no, genera una versión actualizada. En práctica, hay un problema: la re-planificación consume tokens y tiempo. Sin límites, un agente puede entrar en un bucle donde replanifica constantemente sin ejecutar nada.
La solución es un presupuesto de re-planificación. Los sistemas suelen limitar el numero de planificaciones para evitar loops, típicamente mediante un presupuesto fijo definido por el diseñador del sistema. Si el agente agota ese presupuesto, ejecuta el plan actual o reporta el bloqueo. Además, cada planificación debe justificar por qué el plan anterior era insuficiente, lo que filtra las re-planificaciones innecesarias.
Ejemplo: Planning dinámico con LangGraph
from langgraph.graph import StateGraph, END
from typing import TypedDict
class PlanningState(TypedDict):
goal: str
plan: list
current_step: int
results: list
max_replans: int
replan_count: int
should_replan: bool
def plan_node(state: PlanningState) -> PlanningState:
"""Genera o re-planifica basado en el objetivo y resultados anteriores."""
# En producción: llamada al LLM para generar/revisar el plan
plan = [
{"step": 1, "action": "investigar_contexto", "depends_on": []},
{"step": 2, "action": "recopilar_datos", "depends_on": [1]},
{"step": 3, "action": "analizar_resultados", "depends_on": [2]},
{"step": 4, "action": "generar_conclusion", "depends_on": [3]},
]
return {**state, "plan": plan, "current_step": 0, "replan_count": 0, "should_replan": False}
def execute_step(state: PlanningState) -> PlanningState:
"""Ejecuta el paso actual del plan."""
step = state["plan"][state["current_step"]]
# En producción: ejecutar la acción real (tool call, LLM call, etc.)
result = f"Resultado de: {step['action']}"
return {
**state,
"results": state["results"] + [result],
"current_step": state["current_step"] + 1,
}
def evaluate_step(state: PlanningState) -> PlanningState:
"""Evalúa si el resultado justifica re-planificar."""
# En producción, esto seria un LLM judge o heuristica basada en:
# - discrepancia entre output esperado vs obtenido
# - cambio en observaciones de herramientas
# - confidence score bajo
# Aqui simulamos: re-planificar si el paso actual fue el 2
should_replan = (state["current_step"] == 2 and
state["replan_count"] < state.get("max_replans", 3))
if should_replan:
state["replan_count"] += 1
return {**state, "should_replan": should_replan}
def routing_logic(state: PlanningState) -> str:
"""Decide la siguiente acción: continuar, re-planificar o terminar."""
if state["current_step"] >= len(state["plan"]):
return "done"
if state["should_replan"]:
return "replan"
return "continue"
def build_planning_graph():
graph = StateGraph(PlanningState)
graph.add_node("plan", plan_node)
graph.add_node("execute", execute_step)
graph.add_node("evaluate", evaluate_step)
graph.set_entry_point("plan")
graph.add_edge("plan", "execute")
graph.add_edge("execute", "evaluate")
graph.add_conditional_edges("evaluate", routing_logic, {
"continue": "execute",
"replan": "plan",
"done": END,
})
return graph.compile()
# Usar el grafo
app = build_planning_graph()
result = app.invoke({
"goal": "Analizar tendencias de IA en 2026",
"results": [],
"max_replans": 3,
"plan": [],
"current_step": 0,
"replan_count": 0,
"should_replan": False,
})
print(result["results"])LangGraph permite modelar Planning como un grafo de estados explícito. El grafo tiene tres nodos: plan (genera/revisa el plan), execute (ejecuta el paso actual), y evaluate (decide si re-planificar). Las transiciones condicionales controlan el flujo: Si evaluate decide que el contexto cambió, el grafo vuelve al nodo plan. La ventaja sobre un loop simple es que el grafo es inspeccionable, puedes ver exactamente en qué estado está el agente y por qué tomó una decisión.
Deep Research: Un caso aplicado
Sistemas como Deep Research combinan planificación ligera, búsqueda iterativa, reformulación de consultas, ranking de resultados, retrieval scoring y síntesis incremental con compresión de contexto. No es Planning puro, sino un loop donde el agente decide que buscar, evalúa los resultados, detecta gaps y genera nuevas queries. La transparencia en los pasos intermedios es lo que permite auditar el proceso.
Tabla comparativa: Planning vs alternativas
| Factor | Planning | Workflow fijo | Prompt único |
|---|---|---|---|
| Flexibilidad | Alta (se adapta al contexto) | Nula (camino predeterminado) | Baja (un solo paso) |
| Previsibilidad | Media (depende del modelo) | Alta (determinista) | Alta |
| Latencia | Alta (plan + ejecución + re-plan) | Baja | Mínima |
| Complejidad | Alta (gestión de estado, re-plan) | Baja | Mínima |
| Depuración | Media (requiere logging de pasos) | Fácil (traza determinista) | Difícil (caja negra) |
| Caso ideal | Objetivos complejos, camino incierto | Procesos repetitivos, camino conocido | Tareas simples, un solo paso |
Observabilidad
Un sistema de Planning sin métricas es un plan que nadie puede auditar. Estos son los indicadores mínimos:
- Profundidad del plan: Número de pasos generados. Si tiende a crecer sin límite, el modelo no sabe cuándo detener la descomposición.
- Tasa de re-planificación: Cuántas veces el plan se modificó. Un valor alto indica que el plan inicial era insuficiente o que el dominio es inherentemente incierto.
- Tasa de completitud: Porcentaje de pasos ejecutados respecto al plan total. Si muchos pasos se abandonan, el plan era realista en teoría pero no en práctica.
- Latencia por fase: Tiempo en planificación vs ejecución. Una metrica util en producción es el ratio de tiempo invertido en planificación vs ejecución, aunque el umbral depende del dominio.
- Trace de decisiones: Registro de cada decisión de re-planificación con su justificación. Sin esto, no puedes distinguir entre un agente que se adapta y uno que está perdido.
En producción, mantenemos un log estructurado por paso: {step_id, action, input_summary, output_summary, duration_ms, replan_reason}. Eso es suficiente para reconstruir cualquier ejecución y entender por qué el agente tomó cada decisión.
Planning combinado con otros patrones
Planning rara vez opera solo. Se integra con los patrones que ya hemos cubierto:
Con Tool Use, el plan determina qué herramientas llamar y en qué orden. Cada paso del plan puede invocar herramientas diferentes, y los resultados de las herramientas alimentan la decisión de re-planificar.
Con Reflection, cada paso del plan pasa por un Critic antes de considerarse completo. El Critic evalúa si el output cumple el criterio de éxito definido en el plan. Si no, el paso se re-ejecuta o el plan se ajusta.
Con Routing, el router decide si una petición merece Planning o puede resolverse con un flujo más simple. Peticiones directas van al modelo. Peticiones complejas van al planificador.
Con Parallelization, los pasos del plan que no tienen dependencias entre sí se ejecutan concurrentemente. Si el plan tiene pasos A, B, C donde B y C dependen solo de A, entonces B y C corren en paralelo después de A.
Failure modes del Planning
En produccion, Planning falla de formas especificas que conviene anticipar:
- Error propagado entre pasos: Si el paso 1 produce un output ligeramente incorrecto, los pasos 2-N se ejecutan sobre una base errónea. El error se amplifica en lugar de corregirse.
- Planes basados en supuestos incorrectos: El plan parece perfecto pero se basa en información incompleta o desactualizada desde el paso 1. Nadie lo detecta hasta el final.
- Tool hallucination en el plan: El agente genera un plan que referencia herramientas que no existen o usa parámetros inválidos. El plan es estructuralmente correcto pero no ejecutable.
- Acumulación de errores en pipelines largos: Cada paso introduce un pequeño error. En pipelines de 10+ pasos, los errores se acumulan hasta que el output final es significativamente peor que el input.
- Sobreplanning (over-decomposition): Descomponer una tarea en demasiados pasos añade latencia sin mejorar la calidad. Un plan de 15 pasos para una tarea que se podía resolver en 3 es overhead puro.
La defensa común a todos estos failure modes es evaluación intermedia, verificar la calidad de cada paso antes de continuar, no solo al final. Sin evaluación intermedia, Planning es una caja negra que solo revela sus fallos cuando ya es tarde.
En la práctica, estos sistemas son probabilísticos y propensos a fallos parciales en cada etapa. Los agentes son ruidosos, las herramientas fallan parcialmente, y el planning no es determinista. Un diseño robusto asume fallos y los gestiona, en lugar de asumir que el flujo sera limpio.
Anti-patrones
- Planificar tareas simples: Si un prompt o una herramienta resuelve la tarea, Planning añade latencia sin valor. La prueba es directa, ejecuta sin plan y compara resultados.
- Plan rígido sin re-planificación: Un plan que no se adapta al primer obstáculo es un workflow disfrazado. Si usas Planning, implementa re-planificación o usa un workflow fijo.
- Bucles de planificación infinitos: El agente re-planifica sin ejecutar. Sin un presupuesto máximo de planificaciones, esto es el fallo más común.
- Sin transparencia en los pasos: Sin logging de las decisiones intermedias, un plan fallido es indistinguible de una alucinación. Expón los pasos.
- Descomposición sin criterios de éxito: Un paso sin criterio de salida claro no es ejecutable. «Investigar el tema» es vago. «Identificar 3 fuentes primarias y resumir cada una en 100 palabras» es accionable.
- Plan plausible pero incorrecto: El peligro más silencioso. El plan parece perfecto, cada paso es razonable, pero se basa en supuestos erróneos desde el paso 1. Nadie lo detecta hasta el final y el output entero esta viciado. La defensa común es evaluación intermedia, verificar la calidad de cada paso antes de continuar, no solo al final.
- Ignorar el trade-off previsibilidad vs flexibilidad: Planning dinámico es más flexible pero menos predecible. En sistemas críticos, el plan debe tener restricciones explícitas.
Conclusión
Planning es un conjunto de técnicas de orquestación de agentes LLM que descomponen objetivos en pasos ejecutables, potencialmente con planificación inicial, ejecución iterativa y replanificación basada en feedback. Sin este tipo de orquestación, los agentes tienden a intentar resolver tareas en un único paso y producen outputs superficiales. Con el, pueden descomponer, ejecutar y adaptarse.
Planning es un sistema de control con trade-offs explícitos entre cuatro dimensiones: Costo (latencia y tokens), robustez (capacidad de replanificación), previsibilidad (grado de determinismo) y adaptabilidad (feedback loops). Optimizar una dimensión suele degradar otra. Un sistema con alta robustez y alta adaptabilidad tiende a tener alto costo y baja previsibilidad. El diseño consiste en elegir los trade-offs que mejor se alinean con el caso de uso.
La pregunta que define si Planning vale la pena es simple: ¿El camino hacia el resultado se conoce de antemano? Si la respuesta es sí, usa un workflow. Si la respuesta es no, Planning es la herramienta correcta, siempre que implementes planificación con límites, transparencia en los pasos intermedios, y métricas que te digan si el plan está funcionando o si el agente está dando vueltas en círculos.
Planning no mejora la inteligencia del sistema; mejora su estructura bajo incertidumbre. No se trata de que un modelo mas pequeño se vuelva mas capaz, sino de que un modelo con Planning obtiene mejor desempeño en tareas multi-step bajo restricciones. La diferencia no esta en el modelo, esta en la arquitectura.
¿Cuándo debo usar Planning?
Cuando una tarea requiere más de un paso y el camino no es fijo. Si puedes manejarlo con un solo prompt o una herramienta, Planning es overhead innecesario. Úsalo cuando el «cómo» se descubre durante la ejecución: Investigación, análisis, diseño de sistemas.
¿Cuál es la diferencia entre Planning estático y dinámico?
El Planning estático genera el plan una vez y lo sigue. Es predecible y funciona para procesos repetitivos. El dinámico permite que el plan evolucione durante la ejecución según nueva información o obstáculos. Para dominios inciertos, el dinámico es esencial, pero añade latencia y complejidad.
¿Qué es el patrón Planner-Writer?
Un agente que primero genera un plan estructurado y luego lo ejecuta paso a paso. Es la forma más simple de Planning. Un solo agente que planifica y actúa. Cuando cada paso requiere especialización distinta, escalas a multi-agente.
¿Cómo evito que el agente entre en bucles de planificación?
Establece un presupuesto máximo de planificaciones. El valor depende del dominio y la tolerancia a latencia. Si el agente planifica más de ese límite, ejecuta el plan actual o reporta el bloqueo. Registra los pasos ya ejecutados y exige justificación para cada planificación.
¿Planning funciona con modelos locales?
Sí, pero la calidad de la descomposición escala con el tamaño del modelo. Modelos de 7B generan planes superficiales; pasos genéricos sin dependencias claras. Los de 13B+ manejan descomposiciones razonables. Los de 30B+ producen planes estructurados con dependencias correctas y criterios de éxito definidos. Para Planning en producción, 13B es el mínimo práctico.
¿Cómo mido si el Planning mejora la calidad del output?
Compara outputs con y sin Planning en el mismo conjunto de tareas. Mide tres indicadores: Completitud (¿Cubrió todos los aspectos?), coherencia (¿El output sigue la estructura del plan?) y tasa de re-planificación (¿El plan original era suficiente?). Si Planning no mejora estos indicadores de forma consistente, probablemente no lo necesitas.